
Extractive Text Summarization
What is text summarization?
Text summarization is the process of creating a short, accurate, and fluent summary of a longer text document. It is the process of distilling the most important information from a source text. Automatic text summarization is a common problem in machine learning and natural language processing (NLP). Automatic text summarization methods are greatly needed to address the ever-growing amount of text data available online to both better help discover relevant information and to consume relevant information faster.
Why automatic text summarization?
- Summaries reduce reading time.
- While researching using various documents, summaries make the selection process easier.
- Automatic summarization improves the effectiveness of indexing.
- Automatic summarization algorithms are less biased than human summarizers.
- Personalized summaries are useful in question-answering systems as they provide personalized information.
- Using automatic or semi-automatic summarization systems enables commercial abstract services to - increase the number of text documents they are able to process.
Type of summarization
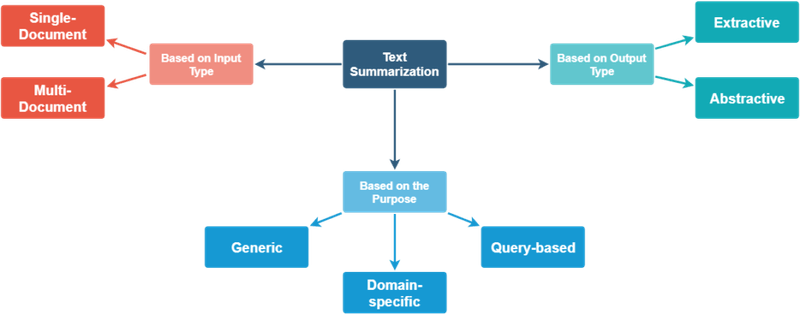
- An
Extractive summarizationmethod consists of selecting important sentences, paragraphs etc. from the original document and concatenating them into shorter form. - An
Abstractive summarizationis an understanding of the main concepts in a document and then express those concepts in clear natural language. - The
Domain-specific summarizationtechniques utilize the available knowledge specific to the domain of text. For example, automatic summarization research on medical text generally attempts to utilize the various sources of codified medical knowledge and ontologies. - The
Generic summarizationfocuses on obtaining a generic summary or abstract of the collection of documents, or sets of images, or videos, news stories etc. - The
Query-based summarization, sometimes called query-relevant summarization, summarizes objects specific to a query. - The
Multi-document summarizationis an automatic procedure aimed at extraction of information from multiple texts written about the same topic. Resulting summary report allows individual users, such as professional information consumers, to quickly familiarize themselves with information contained in a large cluster of documents. - The
Single-document summarizationgenerates a summary from a single source document.
How to do text summarization
- Text cleaning
- Sentence Tokenization
- Word tokenization
- Word-frequency table
- Summarization
Text
This is the piece of text which we will be using in this project. We will perform extractive summarization of this text.
text = """
There are broadly two types of extractive summarization tasks depending on what the summarization program focuses on. The first is generic summarization, which focuses on obtaining a generic summary or abstract of the collection (whether documents, or sets of images, or videos, news stories etc.). The second is query relevant summarization, sometimes called query-based summarization, which summarizes objects specific to a query. Summarization systems are able to create both query relevant text summaries and generic machine-generated summaries depending on what the user needs.
An example of a summarization problem is document summarization, which attempts to automatically produce an abstract from a given document. Sometimes one might be interested in generating a summary from a single source document, while others can use multiple source documents (for example, a cluster of articles on the same topic). This problem is called multi-document summarization. A related application is summarizing news articles. Imagine a system, which automatically pulls together news articles on a given topic (from the web), and concisely represents the latest news as a summary.
Image collection summarization is another application example of automatic summarization. It consists in selecting a representative set of images from a larger set of images.[3] A summary in this context is useful to show the most representative images of results in an image collection exploration system. Video summarization is a related domain, where the system automatically creates a trailer of a long video. This also has applications in consumer or personal videos, where one might want to skip the boring or repetitive actions. Similarly, in surveillance videos, one would want to extract important and suspicious activity, while ignoring all the boring and redundant frames captured.
"""Let's Get Started with SpaCy
You can install SpaCy using the following commands:-
pip install -U spacy
python -m spacy download en_core_web_smWe will import all the necessary libraries.
spacyfor Natural Language Processing.STOP_WORDSis a set of default stop words for English language model in SpaCy.punctuationis a pre-initialized string which will give the all sets of punctuation.
import spacy
from spacy.lang.en.stop_words import STOP_WORDS
from string import punctuationHere we will create a list of stopwords.
stopwords = list(STOP_WORDS)spacy.load is used to load a model. spacy.load('en_core_web_sm') loads the model package en_core_web_sm. This will return a language object nlp containing all components and data needed to process text.
nlp = spacy.load('en_core_web_sm')Calling the nlp object on a string of text will return a processed Doc. During processing, spaCy first tokenizes the text, i.e. segments it into words, punctuation and so on.
doc = nlp(text)Each Doc consists of individual tokens, and we can iterate over them. Now we will make a list of tokens called tokens.
tokens = [token.text for token in doc]
print(tokens)['\n', 'There', 'are', 'broadly', 'two', 'types', 'of', 'extractive', 'summarization', 'tasks', 'depending', 'on', 'what', 'the', 'summarization', 'program', 'focuses', 'on', '.', 'The', 'first', 'is', 'generic', 'summarization', ',', 'which', 'focuses', 'on', 'obtaining', 'a', 'generic', 'summary', 'or', 'abstract', 'of', 'the', 'collection', '(', 'whether', 'documents', ',', 'or', 'sets', 'of', 'images', ',', 'or', 'videos', ',', 'news', 'stories', 'etc', '.', ')', '.', 'The', 'second', 'is', 'query', 'relevant', 'summarization', ',', 'sometimes', 'called', 'query', '-', 'based', 'summarization', ',', 'which', 'summarizes', 'objects', 'specific', 'to', 'a', 'query', '.', 'Summarization', 'systems', 'are', 'able', 'to', 'create', 'both', 'query', 'relevant', 'text', 'summaries', 'and', 'generic', 'machine', '-', 'generated', 'summaries', 'depending', 'on', 'what', 'the', 'user', 'needs', '.', '\n', 'An', 'example', 'of', 'a', 'summarization', 'problem', 'is', 'document', 'summarization', ',', 'which', 'attempts', 'to', 'automatically', 'produce', 'an', 'abstract', 'from', 'a', 'given', 'document', '.', 'Sometimes', 'one', 'might', 'be', 'interested', 'in', 'generating', 'a', 'summary', 'from', 'a', 'single', 'source', 'document', ',', 'while', 'others', 'can', 'use', 'multiple', 'source', 'documents', '(', 'for', 'example', ',', 'a', 'cluster', 'of', 'articles', 'on', 'the', 'same', 'topic', ')', '.', 'This', 'problem', 'is', 'called', 'multi', '-', 'document', 'summarization', '.', 'A', 'related', 'application', 'is', 'summarizing', 'news', 'articles', '.', 'Imagine', 'a', 'system', ',', 'which', 'automatically', 'pulls', 'together', 'news', 'articles', 'on', 'a', 'given', 'topic', '(', 'from', 'the', 'web', ')', ',', 'and', 'concisely', 'represents', 'the', 'latest', 'news', 'as', 'a', 'summary', '.', '\n', 'Image', 'collection', 'summarization', 'is', 'another', 'application', 'example', 'of', 'automatic', 'summarization', '.', 'It', 'consists', 'in', 'selecting', 'a', 'representative', 'set', 'of', 'images', 'from', 'a', 'larger', 'set', 'of', 'images.[3', ']', 'A', 'summary', 'in', 'this', 'context', 'is', 'useful', 'to', 'show', 'the', 'most', 'representative', 'images', 'of', 'results', 'in', 'an', 'image', 'collection', 'exploration', 'system', '.', 'Video', 'summarization', 'is', 'a', 'related', 'domain', ',', 'where', 'the', 'system', 'automatically', 'creates', 'a', 'trailer', 'of', 'a', 'long', 'video', '.', 'This', 'also', 'has', 'applications', 'in', 'consumer', 'or', 'personal', 'videos', ',', 'where', 'one', 'might', 'want', 'to', 'skip', 'the', 'boring', 'or', 'repetitive', 'actions', '.', 'Similarly', ',', 'in', 'surveillance', 'videos', ',', 'one', 'would', 'want', 'to', 'extract', 'important', 'and', 'suspicious', 'activity', ',', 'while', 'ignoring', 'all', 'the', 'boring', 'and', 'redundant', 'frames', 'captured', '.', '\n']We can see that all the punctuation marks and special characters are included in the tokens. Now we will remove them. punctuation contains a string of all the punctuations but it does now conatin \n. So we will add \n in punctuation.
punctuation = punctuation + '\n'
punctuation'!"#$%&\'()*+,-./:;?@[\\]^_`{|}~\n'Now we will make the word frequency table. It will contain the number of occurrences of all the distinct words in the text which are not punctuations or stop words. We will create a dictionary named word_frequencies.
word_frequencies = {}
for word in doc:
if word.text.lower() not in stopwords:
if word.text.lower() not in punctuation:
if word.text not in word_frequencies.keys():
word_frequencies[word.text] = 1
else:
word_frequencies[word.text] += 1
print(word_frequencies){'broadly': 1, 'types': 1, 'extractive': 1, 'summarization': 11, 'tasks': 1, 'depending': 2, 'program': 1, 'focuses': 2, 'generic': 3, 'obtaining': 1, 'summary': 4, 'abstract': 2, 'collection': 3, 'documents': 2, 'sets': 1, 'images': 3, 'videos': 3, 'news': 4, 'stories': 1, 'etc': 1, 'second': 1, 'query': 4, 'relevant': 2, 'called': 2, 'based': 1, 'summarizes': 1, 'objects': 1, 'specific': 1, 'Summarization': 1, 'systems': 1, 'able': 1, 'create': 1, 'text': 1, 'summaries': 2, 'machine': 1, 'generated': 1, 'user': 1, 'needs': 1, 'example': 3, 'problem': 2, 'document': 4, 'attempts': 1, 'automatically': 3, 'produce': 1, 'given': 2, 'interested': 1, 'generating': 1, 'single': 1, 'source': 2, 'use': 1, 'multiple': 1, 'cluster': 1, 'articles': 3, 'topic': 2, 'multi': 1, 'related': 2, 'application': 2, 'summarizing': 1, 'Imagine': 1, 'system': 3, 'pulls': 1, 'web': 1, 'concisely': 1, 'represents': 1, 'latest': 1, 'Image': 1, 'automatic': 1, 'consists': 1, 'selecting': 1, 'representative': 2, 'set': 2, 'larger': 1, 'images.[3': 1, 'context': 1, 'useful': 1, 'results': 1, 'image': 1, 'exploration': 1, 'Video': 1, 'domain': 1, 'creates': 1, 'trailer': 1, 'long': 1, 'video': 1, 'applications': 1, 'consumer': 1, 'personal': 1, 'want': 2, 'skip': 1, 'boring': 2, 'repetitive': 1, 'actions': 1, 'Similarly': 1, 'surveillance': 1, 'extract': 1, 'important': 1, 'suspicious': 1, 'activity': 1, 'ignoring': 1, 'redundant': 1, 'frames': 1, 'captured': 1}Now we will get the max_frequency.
max_frequency = max(word_frequencies.values())
max_frequency11We will divide each frequency value in word_frequencies with the max_frequency to normalize the frequencies.
for word in word_frequencies.keys():
word_frequencies[word] = word_frequencies[word]/max_frequency
print(word_frequencies){'broadly': 0.09090909090909091, 'types': 0.09090909090909091, 'extractive': 0.09090909090909091, 'summarization': 1.0, 'tasks': 0.09090909090909091, 'depending': 0.18181818181818182, 'program': 0.09090909090909091, 'focuses': 0.18181818181818182, 'generic': 0.2727272727272727, 'obtaining': 0.09090909090909091, 'summary': 0.36363636363636365, 'abstract': 0.18181818181818182, 'collection': 0.2727272727272727, 'documents': 0.18181818181818182, 'sets': 0.09090909090909091, 'images': 0.2727272727272727, 'videos': 0.2727272727272727, 'news': 0.36363636363636365, 'stories': 0.09090909090909091, 'etc': 0.09090909090909091, 'second': 0.09090909090909091, 'query': 0.36363636363636365, 'relevant': 0.18181818181818182, 'called': 0.18181818181818182, 'based': 0.09090909090909091, 'summarizes': 0.09090909090909091, 'objects': 0.09090909090909091, 'specific': 0.09090909090909091, 'Summarization': 0.09090909090909091, 'systems': 0.09090909090909091, 'able': 0.09090909090909091, 'create': 0.09090909090909091, 'text': 0.09090909090909091, 'summaries': 0.18181818181818182, 'machine': 0.09090909090909091, 'generated': 0.09090909090909091, 'user': 0.09090909090909091, 'needs': 0.09090909090909091, 'example': 0.2727272727272727, 'problem': 0.18181818181818182, 'document': 0.36363636363636365, 'attempts': 0.09090909090909091, 'automatically': 0.2727272727272727, 'produce': 0.09090909090909091, 'given': 0.18181818181818182, 'interested': 0.09090909090909091, 'generating': 0.09090909090909091, 'single': 0.09090909090909091, 'source': 0.18181818181818182, 'use': 0.09090909090909091, 'multiple': 0.09090909090909091, 'cluster': 0.09090909090909091, 'articles': 0.2727272727272727, 'topic': 0.18181818181818182, 'multi': 0.09090909090909091, 'related': 0.18181818181818182, 'application': 0.18181818181818182, 'summarizing': 0.09090909090909091, 'Imagine': 0.09090909090909091, 'system': 0.2727272727272727, 'pulls': 0.09090909090909091, 'web': 0.09090909090909091, 'concisely': 0.09090909090909091, 'represents': 0.09090909090909091, 'latest': 0.09090909090909091, 'Image': 0.09090909090909091, 'automatic': 0.09090909090909091, 'consists': 0.09090909090909091, 'selecting': 0.09090909090909091, 'representative': 0.18181818181818182, 'set': 0.18181818181818182, 'larger': 0.09090909090909091, 'images.[3': 0.09090909090909091, 'context': 0.09090909090909091, 'useful': 0.09090909090909091, 'results': 0.09090909090909091, 'image': 0.09090909090909091, 'exploration': 0.09090909090909091, 'Video': 0.09090909090909091, 'domain': 0.09090909090909091, 'creates': 0.09090909090909091, 'trailer': 0.09090909090909091, 'long': 0.09090909090909091, 'video': 0.09090909090909091, 'applications': 0.09090909090909091, 'consumer': 0.09090909090909091, 'personal': 0.09090909090909091, 'want': 0.18181818181818182, 'skip': 0.09090909090909091, 'boring': 0.18181818181818182, 'repetitive': 0.09090909090909091, 'actions': 0.09090909090909091, 'Similarly': 0.09090909090909091, 'surveillance': 0.09090909090909091, 'extract': 0.09090909090909091, 'important': 0.09090909090909091, 'suspicious': 0.09090909090909091, 'activity': 0.09090909090909091, 'ignoring': 0.09090909090909091, 'redundant': 0.09090909090909091, 'frames': 0.09090909090909091, 'captured': 0.09090909090909091}Now we will do sentence tokenization. The entire text is divided into sentences.
sentence_tokens = [sent for sent in doc.sents]
print(sentence_tokens)[
There are broadly two types of extractive summarization tasks depending on what the summarization program focuses on., The first is generic summarization, which focuses on obtaining a generic summary or abstract of the collection (whether documents, or sets of images, or videos, news stories etc.)., The second is query relevant summarization, sometimes called query-based summarization, which summarizes objects specific to a query., Summarization systems are able to create both query relevant text summaries and generic machine-generated summaries depending on what the user needs.
, An example of a summarization problem is document summarization, which attempts to automatically produce an abstract from a given document., Sometimes one might be interested in generating a summary from a single source document, while others can use multiple source documents (for example, a cluster of articles on the same topic)., This problem is called multi-document summarization., A related application is summarizing news articles., Imagine a system, which automatically pulls together news articles on a given topic (from the web), and concisely represents the latest news as a summary.
, Image collection summarization is another application example of automatic summarization., It consists in selecting a representative set of images from a larger set of images.[3], A summary in this context is useful to show the most representative images of results in an image collection exploration system., Video summarization is a related domain, where the system automatically creates a trailer of a long video., This also has applications in consumer or personal videos, where one might want to skip the boring or repetitive actions., Similarly, in surveillance videos, one would want to extract important and suspicious activity, while ignoring all the boring and redundant frames captured.
]Now we will calculate the sentence scores. The sentence score for a particular sentence is the sum of the normalized frequencies of the words in that sentence. All the sentences will be stored with their score in the dictionary sentence_scores.
sentence_scores = {}
for sent in sentence_tokens:
for word in sent:
if word.text.lower() in word_frequencies.keys():
if sent not in sentence_scores.keys():
sentence_scores[sent] = word_frequencies[word.text.lower()]
else:
sentence_scores[sent] += word_frequencies[word.text.lower()]
sentence_scores{There are broadly two types of extractive summarization tasks depending on what the summarization program focuses on.: 2.818181818181818, The first is generic summarization, which focuses on obtaining a generic summary or abstract of the collection (whether documents, or sets of images, or videos, news stories etc.).: 3.9999999999999987, The second is query relevant summarization, sometimes called query-based summarization, which summarizes objects specific to a query.: 3.909090909090909, Summarization systems are able to create both query relevant text summaries and generic machine-generated summaries depending on what the user needs.: 3.09090909090909, An example of a summarization problem is document summarization, which attempts to automatically produce an abstract from a given document.: 3.9999999999999996, Sometimes one might be interested in generating a summary from a single source document, while others can use multiple source documents (for example, a cluster of articles on the same topic).: 2.545454545454545, This problem is called multi-document summarization.: 1.8181818181818183, A related application is summarizing news articles.: 1.0909090909090908, Imagine a system, which automatically pulls together news articles on a given topic (from the web), and concisely represents the latest news as a summary.: 2.727272727272727, Image collection summarization is another application example of automatic summarization.: 2.909090909090909, It consists in selecting a representative set of images from a larger set of images.[3]: 1.1818181818181817, A summary in this context is useful to show the most representative images of results in an image collection exploration system.: 1.818181818181818, Video summarization is a related domain, where the system automatically creates a trailer of a long video.: 2.2727272727272725, This also has applications in consumer or personal videos, where one might want to skip the boring or repetitive actions.: 1.1818181818181817, Similarly, in surveillance videos, one would want to extract important and suspicious activity, while ignoring all the boring and redundant frames captured.: 1.4545454545454544}Now we are going to select 30% of the sentences having the largest scores. For this we are going to import nlargest from heapq.
from heapq import nlargestWe want the length of summary to be 30% of the original length which is 4. Hence the summary will have 4 sentences.
select_length = int(len(sentence_tokens)*0.3)
select_length4nlargest() will return a list with the select_length largest elements i.e. 4 largest elements from sentence_scores. key = sentence_scores.get specifies a function of one argument that is used to extract a comparison key from each element in sentence_scores.
summary = nlargest(select_length, sentence_scores, key = sentence_scores.get)
summary[An example of a summarization problem is document summarization, which attempts to automatically produce an abstract from a given document., The first is generic summarization, which focuses on obtaining a generic summary or abstract of the collection (whether documents, or sets of images, or videos, news stories etc.)., The second is query relevant summarization, sometimes called query-based summarization, which summarizes objects specific to a query., Summarization systems are able to create both query relevant text summaries and generic machine-generated summaries depending on what the user needs.]Now we will combine this sentence together and make final string which contains the summary.
final_summary = [word.text for word in summary]
summary = ' '.join(final_summary)Now we will display the original text, the summary of the text and the lengths of the original text and the generated summary.
print(text)There are broadly two types of extractive summarization tasks depending on what the summarization program focuses on. The first is generic summarization, which focuses on obtaining a generic summary or abstract of the collection (whether documents, or sets of images, or videos, news stories etc.). The second is query relevant summarization, sometimes called query-based summarization, which summarizes objects specific to a query. Summarization systems are able to create both query relevant text summaries and generic machine-generated summaries depending on what the user needs.
An example of a summarization problem is document summarization, which attempts to automatically produce an abstract from a given document. Sometimes one might be interested in generating a summary from a single source document, while others can use multiple source documents (for example, a cluster of articles on the same topic). This problem is called multi-document summarization. A related application is summarizing news articles. Imagine a system, which automatically pulls together news articles on a given topic (from the web), and concisely represents the latest news as a summary.
Image collection summarization is another application example of automatic summarization. It consists in selecting a representative set of images from a larger set of images.[3] A summary in this context is useful to show the most representative images of results in an image collection exploration system. Video summarization is a related domain, where the system automatically creates a trailer of a long video. This also has applications in consumer or personal videos, where one might want to skip the boring or repetitive actions. Similarly, in surveillance videos, one would want to extract important and suspicious activity, while ignoring all the boring and redundant frames captured.print(summary)An example of a summarization problem is document summarization, which attempts to automatically produce an abstract from a given document. The first is generic summarization, which focuses on obtaining a generic summary or abstract of the collection (whether documents, or sets of images, or videos, news stories etc.). The second is query relevant summarization, sometimes called query-based summarization, which summarizes objects specific to a query. Summarization systems are able to create both query relevant text summaries and generic machine-generated summaries depending on what the user needs.len(text)1869len(summary)605As you the length of the text is reduced from 1869 to 605 after summarization.
Conclusion
In this tutorial you built an extractive text summarizer using spaCy and Python's heapq module — no model training required. Starting from raw text, you scored every word by normalized frequency (ignoring stop words and punctuation), accumulated those scores across each sentence, then selected the top 30% of sentences by score to form the summary. The result compressed a 1,869-character document to 605 characters while retaining the highest-information sentences.
Key takeaways:
- Extractive summarization selects existing sentences rather than generating new text — it is fast, deterministic, and requires no training data.
- Word frequency normalization (dividing by
max_frequency) prevents long documents from unfairly biasing scores toward high-frequency words. heapq.nlargest()efficiently retrieves the top-N sentences by score without sorting the entire dictionary.- The 30% selection threshold is a heuristic; tune it based on your document length and desired compression ratio.
Next steps:
- Extend the pipeline to multi-document summarization by concatenating multiple texts before scoring, then filtering by a stricter threshold.
- Compare extractive output against abstractive summarization using a pre-trained Hugging Face model to see where frequency-based extraction falls short.
- Apply this summarizer to news articles or research papers in NLP Tutorial: Working with Text Files to process real-world documents.

