NLP Tutorial - GloVe Vectors Embedding with TF2.0 and Keras
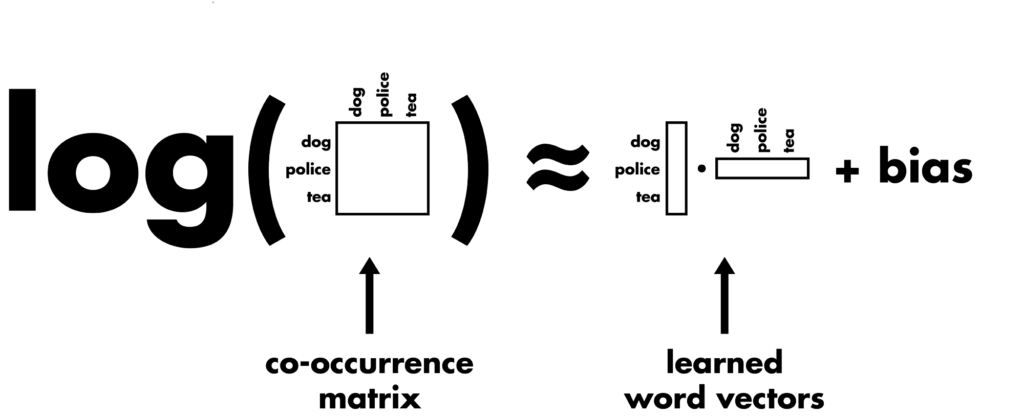
In this blog, we will learn how to use pre-trained GloVe vectors as word embeddings in a TensorFlow 2.0 and Keras model for Twitter sentiment. We load ready-made vectors instead of training our own from scratch.
GloVe stands for global vectors for word representation. It is an unsupervised learning algorithm developed by Stanford for generating word embeddings by aggregating a global word-word co-occurrence matrix from a corpus. The resulting embeddings show interesting linear substructures of the word in vector space.
Ref:
Glove Vectors:
GloVe: Global Vectors for Word Representation
Common Crawl (840B tokens, 2.2M vocab, cased, 300d vectors, 2.03 GB download):
Download glove.840B.300d.zip (2.03 GB)
Twitter (2B tweets, 27B tokens, 1.2M vocab, uncased, 25d, 50d, 100d, & 200d vectors, 1.42 GB download):
Download glove.twitter.27B.zip (1.42 GB)
Watch Full Video:
Notebook Setup
Importing Libraries
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Flatten,Embedding,Activation, Dropout
from tensorflow.keras.layers import Conv1D, MaxPooling1D, GlobalMaxPooling1D
from tensorflow.keras.optimizers import Adam
import numpy as np
from numpy import array
import pandas as pd
from sklearn.model_selection import train_test_split
python
#reading dataset
df = pd.read_csv('twitter4000.csv')
df.head()| twitts | sentiment | |
|---|---|---|
| 0 | is bored and wants to watch a movie any sugge... | 0 |
| 1 | back in miami. waiting to unboard ship | 0 |
| 2 | @misskpey awwww dnt dis brng bak memoriessss, ... | 0 |
| 3 | ughhh i am so tired blahhhhhhhhh | 0 |
| 4 | @mandagoforth me bad! It's funny though. Zacha... | 0 |
Preprocessing and Cleaning
The text preprocessing covers these steps:
- Expanding the contracted words or tokens
- Removing Email
- Removing URLs and HTML tags
- Removing 'RT' retweet tags
- Replacing all non-alphabets values with null
We are defining a dictionary contractions to replace all the short text values with their corresponding expanded values.
#dictionary `contractions` to replace all the short text values with their corresponding the expanded values
#you can add more values as per your requirements.
contractions = {
"ain't": "am not",
"aren't": "are not",
"can't": "cannot",
"can't've": "cannot have",
"'cause": "because",
"could've": "could have",
"couldn't": "could not",
"couldn't've": "could not have",
"didn't": "did not",
"doesn't": "does not",
"don't": "do not",
"hadn't": "had not",
"hadn't've": "had not have",
"hasn't": "has not",
"haven't": "have not",
"he'd": "he would",
"he'd've": "he would have",
"he'll": "he will",
"he'll've": "he will have",
"he's": "he is",
"how'd": "how did",
"how'd'y": "how do you",
"how'll": "how will",
"how's": "how does",
"i'd": "i would",
"i'd've": "i would have",
"i'll": "i will",
"i'll've": "i will have",
"i'm": "i am",
"i've": "i have",
"isn't": "is not",
"it'd": "it would",
"it'd've": "it would have",
"it'll": "it will",
"it'll've": "it will have",
"it's": "it is",
"let's": "let us",
"ma'am": "madam",
"mayn't": "may not",
"might've": "might have",
"mightn't": "might not",
"mightn't've": "might not have",
"must've": "must have",
"mustn't": "must not",
"mustn't've": "must not have",
"needn't": "need not",
"needn't've": "need not have",
"o'clock": "of the clock",
"oughtn't": "ought not",
"oughtn't've": "ought not have",
"shan't": "shall not",
"sha'n't": "shall not",
"shan't've": "shall not have",
"she'd": "she would",
"she'd've": "she would have",
"she'll": "she will",
"she'll've": "she will have",
"she's": "she is",
"should've": "should have",
"shouldn't": "should not",
"shouldn't've": "should not have",
"so've": "so have",
"so's": "so is",
"that'd": "that would",
"that'd've": "that would have",
"that's": "that is",
"there'd": "there would",
"there'd've": "there would have",
"there's": "there is",
"they'd": "they would",
"they'd've": "they would have",
"they'll": "they will",
"they'll've": "they will have",
"they're": "they are",
"they've": "they have",
"to've": "to have",
"wasn't": "was not",
" u ": " you ",
" ur ": " your ",
" n ": " and "}The function get_clean_text() below does all the cleaning steps. It expands the short forms, removes emails, URLs, and HTML tags, strips the RT retweet tags, and replaces all non-alphabet values with null.
%%time
import re
text = ' '.join(df['twitts'])
text = text.split()
freq_comm = pd.Series(text).value_counts()
rare = freq_comm[freq_comm.values == 1]
def get_clean_text(x):
if type(x) is str:
x = x.lower()
for key in contractions:
value = contractions[key]
x = x.replace(key, value)
x = re.sub(r'([a-zA-Z0-9+._-]+@[a-zA-Z0-9._-]+\.[a-zA-Z0-9_-]+)', '', x)
#regex to remove to emails
x = re.sub(r'(http|ftp|https)://([\w_-]+(?:(?:\.[\w_-]+)+))([\w.,@?^=%&:/~+#-]*[\w@?^=%&/~+#-])?', '', x)
#regex to remove URLs
x = re.sub('RT', "", x)
#substitute the 'RT' retweet tags with empty spaces
x = re.sub('[^A-Z a-z]+', '', x)
#combining all the text excluding rare words.
x = ' '.join([t for t in x.split() if t not in rare])
return x
else:
return x
df['twitts'] = df['twitts'].apply(lambda x: get_clean_text(x))Wall time: 567 ms# cleaned tweet text
df['twitts']0 is bored and wants to watch a movie any sugges...
1 back in miami waiting to
2 misskpey awwww dnt bak memoriessss i i am sad lol
3 ughhh i am so tired
4 mandagoforth me bad it is funny though zachary...
...
3995 i just
3996 templating works it all has to be done
3997 mommy just brought me starbucks
3998 omarepps watching you on a house rerunlovin it
3999 thanks for trying to make me smile i will make...
Name: twitts, Length: 4000, dtype: object# sentiment value counts
df['sentiment'].value_counts()1 2000
0 2000
Name: sentiment, dtype: int64# convert to list
text = df['twitts'].tolist()
text[:3]['is bored and wants to watch a movie any suggestions', 'back in miami waiting to', 'misskpey awwww dnt bak memoriessss i i am sad lol']# store sentiment column as target
y = df['sentiment']# fit tokenizer on corpus
token = Tokenizer()
token.fit_on_texts(text)# vocabulary size including padding token
vocab_size = len(token.word_index) + 1
vocab_size6793# convert text to integer sequences
encoded_text = token.texts_to_sequences(text)# print first 3 encoded sequences
print(encoded_text[:3])[[5, 279, 9, 315, 2, 182, 4, 217, 202, 2298], [48, 10, 1299, 183, 2], [2299, 1087, 655, 1300, 2300, 1, 1, 13, 114, 46]]# max_length = 120: truncate/pad all sequences to 120 tokens
# padding='post': append zeros after the sequence if shorter than max_length
max_length = 120
X = pad_sequences(encoded_text, maxlen=max_length, padding='post')print(X)[[ 5 279 9 ... 0 0 0]
[ 48 10 1299 ... 0 0 0]
[2299 1087 655 ... 0 0 0]
...
[ 936 22 925 ... 0 0 0]
[6791 125 7 ... 0 0 0]
[ 88 12 209 ... 0 0 0]]# print padded sequence shape
X.shape(4000, 120)GloVe Vectors
# you -0.11076 0.30786 -0.5198 0.035138 0.10368 -0.052505...... -0.35471 0.2331 -0.0067546 -0.18892 0.27837 -0.38501 -0.11408 0.28191 -0.30946 -0.21878 -0.059105 0.47604 0.05661
#our first text is key and rest are there vector representation in glove# show twitts column
df['twitts']0 is bored and wants to watch a movie any sugges...
1 back in miami waiting to
2 misskpey awwww dnt bak memoriessss i i am sad lol
3 ughhh i am so tired
4 mandagoforth me bad it is funny though zachary...
...
3995 i just
3996 templating works it all has to be done
3997 mommy just brought me starbucks
3998 omarepps watching you on a house rerunlovin it
3999 thanks for trying to make me smile i will make...
Name: twitts, Length: 4000, dtype: object# dict mapping words to GloVe vectors
glove_vectors = dict()%%time
# file = open('glove.twitter.27B.200d.txt', encoding='utf-8')
file = open('glove.twitter.27B.200d.txt', encoding='utf-8')
for line in file:
values = line.split()
word = values[0]
vectors = np.asarray(values[1: ])
# map word to its vector representation
glove_vectors[word] = vectors
file.close()Wall time: 2min 43s# number of loaded GloVe vectors
len(glove_vectors)1193514keys = glove_vectors.keys()
len(keys)1193514We have total 1193514 key values pairs in our dictionary of glove vectors
glove_vectors.get('aassrfdfa')glove_vectors.get('you').shape(200,)Observation:
We can see above that misspelled words are not having their vector representation.
Since we have taken the glove vectors of 200 dimensions, that's why the word 'you' is having 200 values.
The code below creates a matrix for each token in the dataset, populating each row with the GloVe vector for that word. Words not found in GloVe (usernames, misspellings) are printed.
word_vector_matrix = np.zeros((vocab_size, 200))
for word, index in token.word_index.items():
vector = glove_vectors.get(word)
if vector is not None:
word_vector_matrix[index] = vector
else:
print(word)tommcfly
dougiemcfly
donniewahlberg
kirstiealley
quotthe
peterfacinelli
davidarchie
grrrrls
modelsupplies
powersellingmom
princesangelsky
.
.
.
freshplastic
repressd
errrr
wijnia
donniewahlbergllllllloooooooovvvvvvvvvvveeeeeeeeee
markhallcc
scoutnarrator
aeriagames
bballlifeword_vector_matrix[0]array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])Model building
# split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 42, test_size = 0.2, stratify = y)The model uses the TensorFlow Keras library:
Each parameter:
-vocab_size : This is the input dimension in which we will take all the tokens present in our dataset.
-vec_size : This is the size of the vector space in which words will be embedded.
-input_length : This is the length of input sequences, as we would define for any input layer of a Keras model.
-weights : Here we are taking pretrained weights of each word.
-trainable : Here, we do not want to update the learned word weights in this model(since we are using glove vectors here), therefore we will set the trainable attribute for the model to be False.
vec_size = 200
model = Sequential()
model.add(Embedding(vocab_size, vec_size, input_length=max_length, weights = [word_vector_matrix], trainable = False))
model.add(Conv1D(64, 8, activation = 'relu'))
# 64 filters, kernel size 8
model.add(MaxPooling1D(2))
model.add(Dropout(0.5))
model.add(Dense(32, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(16, activation='relu'))
model.add(GlobalMaxPooling1D())
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer=Adam(learning_rate = 0.0001), loss = 'binary_crossentropy', metrics = ['accuracy'])
model.fit(X_train, y_train, epochs = 30, validation_data = (X_test, y_test))Train on 3200 samples, validate on 800 samples
Epoch 1/30
3200/3200 [==============================] - 10s 3ms/sample - loss: 0.7431 - acc: 0.5000 - val_loss: 0.6940 - val_acc: 0.4975
Epoch 2/30
3200/3200 [==============================] - 3s 933us/sample - loss: 0.7102 - acc: 0.5231 - val_loss: 0.6836 - val_acc: 0.5625
Epoch 3/30
3200/3200 [==============================] - 3s 826us/sample - loss: 0.6977 - acc: 0.5384 - val_loss: 0.6781 - val_acc: 0.5975
.
.
.
.
loss: 0.4928 - acc: 0.7688 - val_loss: 0.5388 - val_acc: 0.7387
Epoch 27/30
3200/3200 [==============================] - 2s 730us/sample - loss: 0.4884 - acc: 0.7744 - val_loss: 0.5364 - val_acc: 0.7375
Epoch 28/30
3200/3200 [==============================] - 2s 710us/sample - loss: 0.4819 - acc: 0.7734 - val_loss: 0.5368 - val_acc: 0.7425
Epoch 29/30
3200/3200 [==============================] - 2s 706us/sample - loss: 0.4697 - acc: 0.7837 - val_loss: 0.5320 - val_acc: 0.7337
Epoch 30/30
3200/3200 [==============================] - 3s 810us/sample - loss: 0.4668 - acc: 0.7866 - val_loss: 0.5312 - val_acc: 0.7400# clean and encode text using the same pipeline as training
def get_encode(x):
x = get_clean_text(x)
x = token.texts_to_sequences(x)
x = pad_sequences(x, maxlen=max_length, padding='post')
return xget_encode(["i hi how are you isn't"])array([[ 1, 318, 77, 37, 7, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0]])# predict sentiment class
model.predict_classes(get_encode(['thank you for watching']))array([[1]])Conclusion
In this blog, we built a Twitter sentiment classifier using pre-trained 200-dimensional GloVe Twitter vectors as frozen embedding weights in a Conv1D model. We cleaned 4,000 tweets and encoded them to padded sequences of length 120. We loaded 1.19 million GloVe word vectors into a fixed embedding matrix. The model reached 74% validation accuracy after 30 epochs, without updating any word vectors during training.
Key takeaways:
- Setting
trainable=Falseon the Embedding layer freezes the GloVe weights, so backpropagation cannot overwrite them. This keeps the meaning learned from 27 billion tweets. - Words that are missing from the GloVe vocabulary (usernames, misspellings like "tommcfly") get a zero vector. This is why cleaning the text and dropping rare words improves coverage.
- Conv1D treats each position in the sequence as a spot and learns local n-gram features.
GlobalMaxPooling1Dthen picks the strongest feature across all positions, wherever it appears in the tweet. - Binary cross-entropy with a single sigmoid output node is the right setup for binary sentiment. It predicts
P(positive)directly and does not need a second output for the negative class.
Next steps:
- Replace Conv1D with an LSTM to compare sequential feature learning against the local pattern matching Conv1D uses in IMDB Sentiment Classification with LSTM.
- Try the 300-dimensional Common Crawl GloVe vectors instead of the 200-dimensional Twitter variant to see whether richer embeddings improve accuracy on informal text.
- Fine-tune BERT for the same task in Sentiment Classification Using BERT for a state-of-the-art comparison.




