A reflection agent runs a self-improvement loop. A researcher node gathers information. A critique node checks its quality. If the research falls short, the loop repeats with targeted feedback. This pattern matters for report generation, fact-checking, and competitive analysis, anywhere "good enough on the first try" is not acceptable.
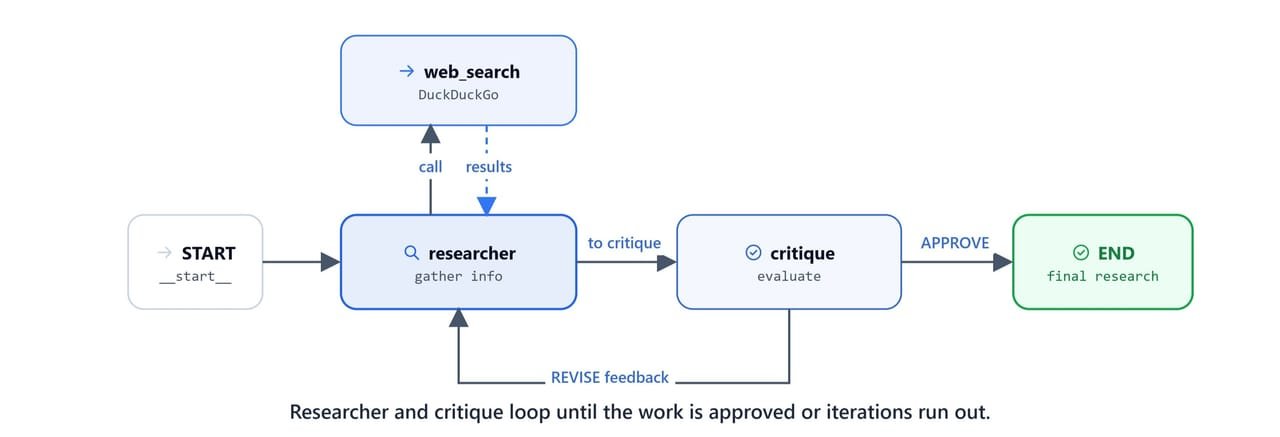
The key idea is the cyclic graph. A standard ReAct agent stops when the LLM stops calling tools. A reflection agent instead loops back from the critique node to the researcher node for more iterations.
Prerequisites: langgraph, langchain-ollama, langchain-core, ddgs, python-dotenv installed. Ollama running with qwen3.
pip install -U langgraph langchain-ollama langchain-core ddgs python-dotenv
ollama pull qwen3Setup
from dotenv import load_dotenv
load_dotenv()from typing_extensions import TypedDict, Annotated
import operator
from langgraph.graph import StateGraph, START, END
from langchain_ollama import ChatOllama
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.tools import tool
from langgraph.prebuilt import ToolNode
# Configuration
BASE_URL = "http://localhost:11434"
MODEL_NAME = "qwen3"
llm = ChatOllama(model=MODEL_NAME, base_url=BASE_URL)Web Search Tool
The researcher node uses DuckDuckGo to search the web for real-time information:
from ddgs import DDGS
@tool
def web_search(query:str, num_results: int = 10) -> str:
"""Use this tool whenever you need to access realtime or latest information.
Search the web using DuckDuckGo.
Args:
query: Search query string
num_results: Number of results to return (default: 5)
Returns:
Formatted search results with titles, descriptions, and URLs
"""
results = DDGS().text(query=query, max_results=num_results, region='us-en')
if not results:
return f"No results found for '{query}'"
formatted_results = [f"Search results for search query: '{query}'"]
for i, result in enumerate(results, 1):
title = result.get('title', 'No title')
href = result.get('href', '')
body = result.get('body', 'No description available')
text = f"{i}. **{title}**\n {body}\n {href}"
formatted_results.append(text)
return "\n\n".join(formatted_results)Agent State
The reflection agent state adds three fields to the standard message list:
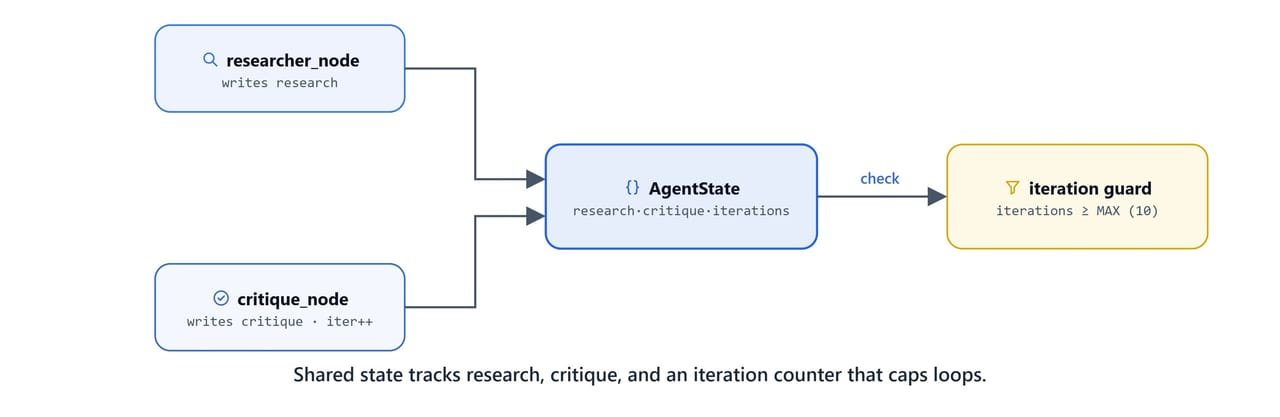
class AgentState(TypedDict):
messages: Annotated[list, operator.add]
research: str
critique: str
iterations: int # track the iteration to avoid infinite loopresearch: the latest research output from the researcher nodecritique: the critique node's evaluation and feedbackiterations: counter to enforceMAX_ITERATIONSand prevent infinite loops
Researcher Node
The researcher node calls web_search to gather information. On later iterations, when critique feedback exists, we inject that feedback into the system prompt. So the researcher targets the specific gaps:
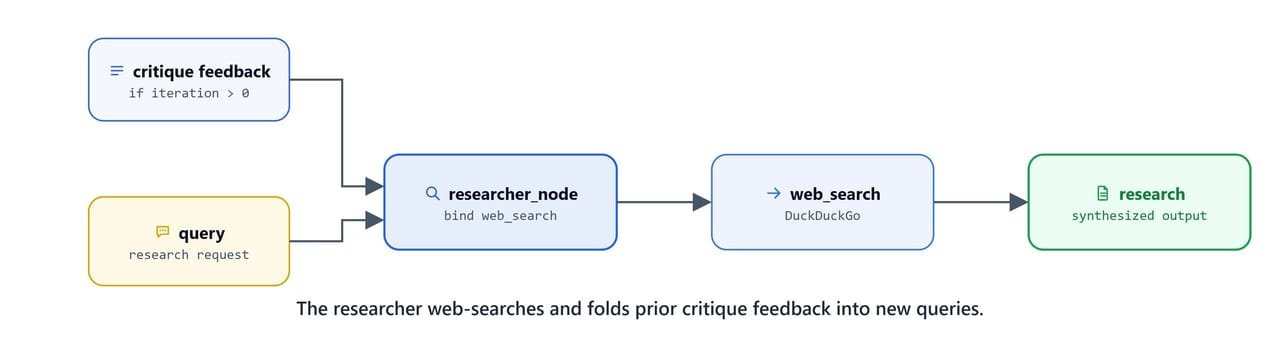
def researcher_node(state: AgentState):
llm_with_tools = llm.bind_tools([web_search])
critique = state.get('critique', '')
iteration = state.get('iterations', 0)
feedback_prompt = ""
if critique:
feedback_prompt = f"""
Previous Critique: {critique}
Address the missing points with new search queries.
"""
system_prompt = SystemMessage(f"""
You are a research agent with web search capabilities.
{feedback_prompt}
INSTRUCTIONS:
1. **MUST use web_search tool** first to gather information
2. Provide comprehensive research based on search results
Always call **web_search** before responding.
""")
messages = [system_prompt] + state['messages']
response = llm_with_tools.invoke(messages)
if hasattr(response, 'tool_calls') and response.tool_calls:
for tc in response.tool_calls:
print(f"[RESEARCHER] called Tool {tc.get('name', '?')} with args {tc.get('args', '?')}")
else:
print(f"[RESEARCHER] Responding with iteration number: {iteration + 1}")
return {"messages": [response]}Critique Node
The critique node checks the researcher's output against two questions. Does it answer the main question? Does it have reasonable detail? It returns either APPROVE (good enough) or REVISE (key information is missing):
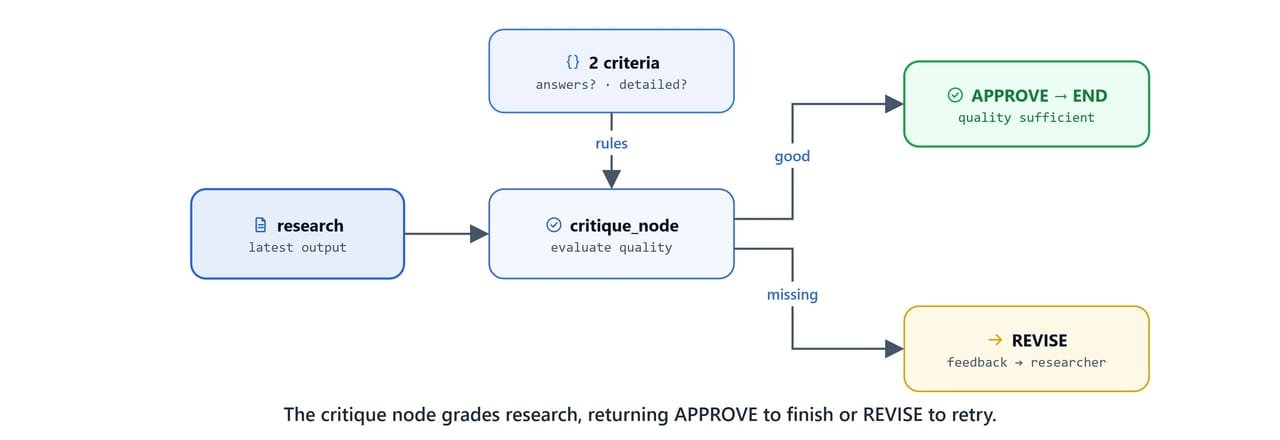
def critique_node(state: AgentState):
messages = state['messages']
iteration = state['iterations']
research_content = messages[-1].content
system_prompt = SystemMessage("""
You are a critique agent. Evaluate if research is good enough.
Check:
1. Does it answer the main question?
2. Is there reasonable detail?
Response Format:
DECISION: APPROVE or REVISE
Be lenient. APPROVE if research is decent enough.
Only REVISE if critical information is completely missing.
""")
critique_prompt = HumanMessage(f"""
Evaluate this research:
{research_content}
""")
messages = [system_prompt, critique_prompt]
response = llm.invoke(messages)
print(f"[CRITIQUE] Iteration {iteration + 1}")
return {
"critique": response.content,
'research': research_content,
'iteration': iteration + 1
}Tip
The critique node uses the base llm without tools. It only needs to judge text, not search the web. This keeps it fast and focused on quality.
Routing Logic
Researcher Router
After the researcher responds, check if it made a tool call (needs to execute the search) or produced a final response (ready for critique):
def should_continue(state: AgentState):
last = state['messages'][-1]
if hasattr(last, 'tool_calls') and last.tool_calls:
return "tools"
else:
return "critique"Critique Router
After the critique node evaluates, check whether to approve (end) or revise (loop back to researcher):
MAX_ITERATIONS = 10
def check_approval(state:AgentState):
critique = state.get('critique', '')
iterations = state.get('iterations', 0)
if iterations >= MAX_ITERATIONS:
print(f"[SYSTEM] Max iterations ({MAX_ITERATIONS}) reached. Stopping...")
return END
if 'APPROVE' in critique.upper():
print(f"[SYSTEM] Research approved after ({iterations} iterations).")
return END
else:
print(f"[SYSTEM] Revision needed. continuing iteration {iterations + 1}")
return "researcher"MAX_ITERATIONS = 10 prevents infinite loops. Even if the critique never approves, the graph stops after 10 cycles.
Build the Graph
def create_agent():
builder = StateGraph(AgentState)
# add nodes
builder.add_node('researcher', researcher_node)
builder.add_node('critique', critique_node)
builder.add_node('tools', ToolNode([web_search]))
# add edges
builder.add_edge(START, 'researcher')
builder.add_conditional_edges('researcher', should_continue, ['tools', 'critique'])
builder.add_edge('tools', 'researcher')
builder.add_conditional_edges('critique', check_approval, ['researcher', END])
graph = builder.compile()
return graph
agent = create_agent()
agentThe cyclic structure: researcher → tools → researcher → critique → researcher (if revised) or critique → END (if approved).
Running the Reflection Agent
Research Query 1: LangGraph Developments
query = "What are the latest developements in the LangGraph for building AI Agents?"
result = agent.invoke({'messages': [HumanMessage(query)], 'iterations':0})
print(result['research'])Here, the agent searches the web, compiles research, gets critiqued, and iterates until approved. The result['research'] field holds the final approved output.
Research Query 2: Stock Price Outlook
query = "What is the latest stock price outlook in 2025 and 2026 for Tesla and Apple?"
result = agent.invoke({'messages': [HumanMessage(query)], 'iterations':0})
print(result['research'])For time-sensitive financial queries, the web search tool pulls current data that the LLM's training data would not have. The critique node makes sure the response includes specific figures and analysis, not generic statements.
The Reflection Loop
What You Built
In this blog, we built a self-improving research agent:
- Extended state:
research,critique, anditerationsfields track the reflection loop state - Researcher node: uses
web_searchto gather information, incorporates critique feedback on subsequent iterations - Critique node: evaluates research quality with
APPROVE/REVISEdecisions - Cyclic graph:
researcher → tools → researcher → critique → (researcher or END), the first LangGraph pattern with a true feedback loop - Iteration guard:
MAX_ITERATIONS = 10prevents infinite revision cycles - Real-time data: DuckDuckGo web search provides current information the LLM's training data lacks
This is how the reflection pattern works. It turns a single-shot Q&A agent into an iterative research system that improves its own output before it answers.



