NLP Tutorial – Spam Text Message Classification using NLP
Spam Ham text classification
Watch Full Video Here
Objective
- Our objective of this code is to classify texts into two classes spam and ham.
What is Natural Language Processing
- Natural Language Processing (NLP) is the field of Artificial Intelligence, where we analyse text using machine learning models
Application of NLP
- Text Classification
- Spam Filters
- Voice text messaging
- Sentiment analysis
- Spell or grammar check
- Chat bot
- Search Suggestion
- Search Autocorrect
- Automatic Review Analysis system
- Machine translation
- And so much more
- Natural Language Understanding (Text classification)
- Natural Language Generation (Text Generation)
The Process of Natural Language Understanding (Text Classification)

Sentence Breakdown

Natural Language Generation

How to get started with NLP
Following are the libraries which are generally used in Natural Language Processing.
- Sklearn
- Spacy
- NLTK
- Gensim
- Tensorflow and Keras
!pip install scikit-learn !python -m spacy download en !pip install -U spacy !pip install gensim !pip install lightgbm

Application of these libraries
- Tokenization
- Parts of Speech Tagging
- Entity Detection
- Dependency Parsing
- Noun Phrases
- Words-to-Vectors Integration
- Context Derivation
- and so much more
Data Cleaning Options
- Case Normalization
- Removing Stop Words
- Removing Punctuations or Special Symbols
- Lemmatization and Stemming
(word normalization) - Parts of Speech Tagging
- Entity Detection
- Bag of Words
- Word-to-Vec
Tokenization
Tokenization is breaking the raw text into small chunks. Tokenization breaks the raw text into words, sentences called tokens. These tokens help in understanding the context or developing the model for the NLP. The tokenization helps in interpreting the meaning of the text by analyzing the sequence of the words.
Parts of Speech Tagging
A Part-Of-Speech Tagger (POS Tagger) is a piece of software that reads text in some language and assigns parts of speech to each word (and other token), such as noun, verb, adjective, etc., although generally computational applications use more fine-grained POS tags like ‘noun-plural.
Entity Detection
Named entity recognition (NER), also known as entity chunking/extraction , is a popular technique used in information extraction to identify and segment the named entities and classify or categorize them under various predefined classes.
Dependency Parsing
Syntactic Parsing or Dependency Parsing is the task of recognizing a sentence and assigning a syntactic structure to it. The most widely used syntactic structure is the parse tree which can be generated using some parsing algorithms. These parse trees are useful in various applications like grammar checking or more importantly it plays a critical role in the semantic analysis stage.
Noun Phrases
Noun phrases are part of speech patterns that include a noun. They can also include whatever other parts of speech make grammatical sense, and can include multiple nouns. Some common noun phrase patterns are:
- Noun
- Noun-Noun..… -Noun
- Adjective(s)-Noun
- Verb-(Adjectives-)Noun
Words-to-Vectors Integration
- Computers interact with humans in programming languages which are unambiguous, precise and often structured. However, natural (human) language has a lot of ambiguity. There are multiple words with same meaning (synonyms), words with multiple meanings (polysemy) some of which are entirely opposite in nature (auto-antonyms), and words which behave differently when used as noun and verb. These words make sense contextually in natural language which humans can comprehend and distinguish easily, but machines can’t. That’s what makes NLP one of the most difficult and interesting tasks in AI.
- Word2Vec is a group of models which helps derive relations between a word and its contextual words.
Case Normalization
Normalization is a process that converts a list of words to a more uniform sequence. For example, converting all words to lowercase will simplify the searching process.
Removing Stop Words
- A stop word is a commonly used word (such as “the”, “a”, “an”, “in”) that a search engine has been programmed to ignore, both when indexing entries for searching and when retrieving them as the result of a search query.
- To check the list of stopwords you can type the following commands in the python shell.
import nltk
from nltk.corpus import stopwords
print(stopwords.words('english'))
Stemming
- Stemming is the process of reducing inflection in words to their root forms such as mapping a group of words to the same stem even if the stem itself is not a valid word in the Language.
Playing -------> Play
Plays ---------> Play
Played --------> Play
Lemmatisation
- Lemmatisation (or lemmatization) in linguistics is the process of grouping together the inflected forms of a word so they can be analysed as a single item, identified by the word’s lemma, or dictionary form.
is,am, are ------> be
Example
the boy's cars are different colors ------> the boy car be differ color
What will be covered in this blog
- Introduction of NLP and Spam detection using sklearn
- Reading Text and PDF files in Python
- Tokenization
- Parts of Speech Tagging
- Word-to-Vectors
- Then real-world practical examples
Bag of Words – The Simples Word Embedding Technique
doc1 = "I am high" doc2 = "Yes I am high" doc3 = "I am kidding"

By comparing the vectors we see that some words are common
Bag of Words and Tf-idf
tf–idf for “Term Frequency times Inverse Document Frequency

Let’s start now the coding part
import numpy as np import pandas as pd import matplotlib.pyplot as plt
df = pd.read_csv('spam.tsv', sep='\t')
df.head()
| label | message | length | punct | |
|---|---|---|---|---|
| 0 | ham | Go until jurong point, crazy.. Available only … | 111 | 9 |
| 1 | ham | Ok lar… Joking wif u oni… | 29 | 6 |
| 2 | spam | Free entry in 2 a wkly comp to win FA Cup fina… | 155 | 6 |
| 3 | ham | U dun say so early hor… U c already then say… | 49 | 6 |
| 4 | ham | Nah I don’t think he goes to usf, he lives aro… | 61 | 2 |
- Now to check whether there is any NULL value in data set we run following code
df.isnull().sum()
label 0 message 0 length 0 punct 0 dtype: int64
len(df)
5572
df['label'].value_counts()
ham 4825 spam 747 Name: label, dtype: int64
- Balancing the data so that we have euqal number of spam and ham messages, so that our machine learning model learns well about both classes while training .
ham = df[df['label']=='ham'] ham.head()
| label | message | length | punct | |
|---|---|---|---|---|
| 0 | ham | Go until jurong point, crazy.. Available only … | 111 | 9 |
| 1 | ham | Ok lar… Joking wif u oni… | 29 | 6 |
| 3 | ham | U dun say so early hor… U c already then say… | 49 | 6 |
| 4 | ham | Nah I don’t think he goes to usf, he lives aro… | 61 | 2 |
| 6 | ham | Even my brother is not like to speak with me. … | 77 | 2 |
spam = df[df['label']=='spam'] spam.head()
| label | message | length | punct | |
|---|---|---|---|---|
| 2 | spam | Free entry in 2 a wkly comp to win FA Cup fina… | 155 | 6 |
| 5 | spam | FreeMsg Hey there darling it’s been 3 week’s n… | 147 | 8 |
| 8 | spam | WINNER!! As a valued network customer you have… | 157 | 6 |
| 9 | spam | Had your mobile 11 months or more? U R entitle… | 154 | 2 |
| 11 | spam | SIX chances to win CASH! From 100 to 20,000 po… | 136 | 8 |
ham.shape, spam.shape
((4825, 4), (747, 4))
ham = ham.sample(spam.shape[0]) ham.shape, spam.shape
((747, 4), (747, 4))
data = ham.append(spam, ignore_index=True) data.tail()
| label | message | length | punct | |
|---|---|---|---|---|
| 1489 | spam | Want explicit SEX in 30 secs? Ring 02073162414… | 90 | 3 |
| 1490 | spam | ASKED 3MOBILE IF 0870 CHATLINES INCLU IN FREE … | 158 | 5 |
| 1491 | spam | Had your contract mobile 11 Mnths? Latest Moto… | 160 | 8 |
| 1492 | spam | REMINDER FROM O2: To get 2.50 pounds free call… | 147 | 3 |
| 1493 | spam | This is the 2nd time we have tried 2 contact u… | 160 | 8 |
Exploratory Data Analysis
plt.hist(data[data['label']=='ham']['length'], bins = 100, alpha = 0.7,label='Ham')
plt.hist(data[data['label']=='spam']['length'], bins = 100, alpha = 0.7,label='Spam')
plt.xlabel('length of messages')
plt.ylabel('Frequency')
plt.legend()
plt.xlim(0,300)
plt.show()

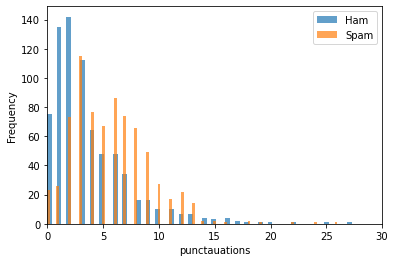
plt.hist(data[data['label']=='ham']['punct'], bins = 100, alpha = 0.7,label='Ham')
plt.hist(data[data['label']=='spam']['punct'], bins = 100, alpha = 0.7,label='Spam')
plt.xlabel('punctauations')
plt.ylabel('Frequency')
plt.legend()
plt.xlim(0,30)
plt.show()
Data Preparation
from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.svm import SVC from sklearn.metrics import accuracy_score, classification_report, confusion_matrix from sklearn.pipeline import Pipeline from sklearn.feature_extraction.text import TfidfVectorizer
data.head()
| label | message | length | punct | |
|---|---|---|---|---|
| 0 | ham | No problem with the renewal. I.ll do it right … | 79 | 3 |
| 1 | ham | Good afternoon, my love! How goes that day ? I… | 160 | 5 |
| 2 | ham | Can come my room but cannot come my house cos … | 77 | 6 |
| 3 | ham | I can send you a pic if you like 🙂 | 35 | 2 |
| 4 | ham | I am on the way to ur home | 26 | 0 |
- Now we convert text data to
word embeddingsusingWord2vec, for that we importgensimlibrary - To convert each message into vector form first we
tokenize each message. - Now we convert each token i.e. each word into wordembedding using word2vec which we import using gensim.
- After converting each word to vector (embedding) we take
average of all word vectors to obtain vector for message. which is finalfeature vectorfor message
import gensim
from nltk.tokenize import word_tokenize
import numpy as np
embedding_dim=100
text=data['message']
Text=[]
for i in range(data.shape[0]):
text1=word_tokenize(text[i])
Text=text1+Text
model= gensim.models.Word2Vec(sentences=[Text], size=embedding_dim, workers=4, min_count=1)
words=list(model.wv.vocab)
# print(text1)
# print(model[text1])
# vector=list(map(lambda x: sum(x)/len(x), zip(*model[text1])))
# print(vector)
def word_2_vec(x):
t1=word_tokenize(x)
model[t1]
v=list(map(lambda y: sum(y)/len(y), zip(*model[t1])))
a=np.array(v)
return a.reshape(1,-1)
- Applying
word2vecto each text message
data['vec']=data['message'].apply(lambda x: word_2_vec(x)) data.head()
| label | message | length | punct | vec | |
|---|---|---|---|---|---|
| 0 | ham | No problem with the renewal. I.ll do it right … | 79 | 3 | [[-0.028193846775037754, -0.000255275213728762… |
| 1 | ham | Good afternoon, my love! How goes that day ? I… | 160 | 5 | [[-0.03519534362069527, -0.0009830875404938859… |
| 2 | ham | Can come my room but cannot come my house cos … | 77 | 6 | [[-0.004332678098257424, -0.000847288884769012… |
| 3 | ham | I can send you a pic if you like 🙂 | 35 | 2 | [[-0.04251667247577147, -0.002708293984390118,… |
| 4 | ham | I am on the way to ur home | 26 | 0 | [[-0.040913782135248766, 0.0017535838996991515… |
- Here we are converting each feature vector pf a message in columns of dataframe
w_vec=np.concatenate(data['vec'].to_numpy(), axis=0) w_vec.shape
(1494, 100)
word_vec=pd.DataFrame(w_vec) word_vec.head()
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | … | 90 | 91 | 92 | 93 | 94 | 95 | 96 | 97 | 98 | 99 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -0.028194 | -0.000255 | -0.005906 | 0.001543 | 0.028490 | 0.008546 | 0.023954 | 0.010250 | 0.043273 | 0.017577 | … | 0.007982 | 0.010225 | 0.031404 | 0.004743 | -0.006825 | 0.008575 | -0.012575 | 0.006858 | -0.012980 | -0.005203 |
| 1 | -0.035195 | -0.000983 | -0.006663 | 0.002052 | 0.033874 | 0.010026 | 0.028198 | 0.011013 | 0.052498 | 0.021042 | … | 0.006637 | 0.012224 | 0.036387 | 0.006481 | -0.008304 | 0.012149 | -0.015957 | 0.009656 | -0.015783 | -0.005901 |
| 2 | -0.004333 | -0.000847 | -0.001710 | 0.000431 | 0.003813 | 0.000388 | 0.003363 | 0.000789 | 0.006293 | 0.003545 | … | 0.000006 | 0.001190 | 0.003674 | 0.001200 | -0.000205 | 0.002153 | -0.000952 | 0.001631 | -0.003232 | 0.001002 |
| 3 | -0.042517 | -0.002708 | -0.007234 | 0.001933 | 0.039980 | 0.010590 | 0.032837 | 0.011987 | 0.062139 | 0.024177 | … | 0.008201 | 0.014543 | 0.043288 | 0.008478 | -0.009570 | 0.012796 | -0.018638 | 0.011211 | -0.018574 | -0.007211 |
| 4 | -0.040914 | 0.001754 | -0.009190 | 0.003661 | 0.040343 | 0.011911 | 0.036438 | 0.013463 | 0.061441 | 0.025578 | … | 0.008912 | 0.014350 | 0.042732 | 0.009705 | -0.010381 | 0.012885 | -0.020183 | 0.011372 | -0.018638 | -0.005238 |
5 rows × 100 columns
X_train, X_test, y_train, y_test = train_test_split(word_vec, data['label'], test_size = 0.3, random_state=0, shuffle = True, stratify=data['label'])
Now we are using different machine learning models for classification of text messages into spam and ham classes
- For
hyperparameter tuningof each model we importGridsearchCV, which tune machine learning model by chossing the optimal paramters for machine learning model - Here we are using
5 fold cross validationin gridsearch method. - By using
cross validation, modelgeneralizes well, that is itperforms well on test data
Support Vector Machine
- In machine learning, support-vector machines (SVMs, also support-vector networks) are
supervised learning modelswith associated learning algorithms that analyze data used for classification and regression analysis. - In addition to performing linear classification, SVMs can efficiently perform a
non-linear classificationusing what is called thekernel trick, implicitly mapping their inputs into high-dimensional feature spaces
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
Parameter_svc=[{'cache_size': [300,400,200],'tol': [0.0011,0.002,0.003],
'kernel': ['rbf','poly'],
'degree': [3,4,5]}]
scores = ['accuracy']
clf_svc = GridSearchCV(SVC(), Parameter_svc, scoring='accuracy', verbose=2, cv=5
)
clf_svc.fit(X_train,y_train)
print(clf_svc.best_params_)
y_pred1 = clf_svc.predict(X_test)
accuracy_score(y_pred1,y_test)
Fitting 5 folds for each of 54 candidates, totalling 270 fits [CV] cache_size=300, degree=3, kernel=rbf, tol=0.0011 ................
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[CV] . cache_size=300, degree=3, kernel=rbf, tol=0.0011, total= 0.3s [CV] cache_size=300, degree=3, kernel=rbf, tol=0.0011 ................ [CV] . cache_size=300, degree=3, kernel=rbf, tol=0.0011, total= 0.1s [CV] cache_size=300, degree=3, kernel=rbf, tol=0.0011 ................
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.2s remaining: 0.0s
0.6993318485523385
LGBMclassifier
- Light GBM is a
gradient boostingframework that uses tree based learning algorithm. - Light GBM
grows tree verticallywhile other algorithm grows trees horizontally meaning that Light GBM grows tree leaf-wise while other algorithm grows level-wise. It will choose the leaf with max delta loss to grow. When growing the same leaf, Leaf-wise algorithm can reduce more loss than a level-wise algorithm.
from lightgbm import LGBMClassifier
Parameter_lgbm=[{'num_leaves':[31,40,50],
'max_depth':[3,4,5,6],
'learning_rate':[0.1,0.05,0.2,0.15],
'n_estimators':[700]}]
scores = ['accuracy']
clf_lgbm = GridSearchCV(LGBMClassifier(), Parameter_lgbm,
scoring='accuracy', verbose=2, cv=5)
clf_lgbm.fit(X_train,y_train)
print(clf_lgbm.best_params_)
y_pred2 = clf_lgbm.predict(X_test)
accuracy_score(y_pred2,y_test)
Fitting 5 folds for each of 48 candidates, totalling 240 fits [CV] learning_rate=0.1, max_depth=3, n_estimators=700, num_leaves=31 .
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[CV] learning_rate=0.1, max_depth=3, n_estimators=700, num_leaves=31, total= 2.7s [CV] learning_rate=0.1, max_depth=3, n_estimators=700, num_leaves=31 .
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 2.6s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 240 out of 240 | elapsed: 8.9min finished
{'learning_rate': 0.2, 'max_depth': 3, 'n_estimators': 700, 'num_leaves': 31}
0.821826280623608
print(classification_report(y_test, y_pred2))
precision recall f1-score support
ham 0.82 0.82 0.82 225
spam 0.82 0.82 0.82 224
accuracy 0.82 449
macro avg 0.82 0.82 0.82 449
weighted avg 0.82 0.82 0.82 449
Random_Forest classifier
- Random forests or random decision forests are an
ensemble learningmethod for classification, regression and other tasks that operate by constructing a multitude of decision trees at training time and outputting the class that is the mode of the classes (classification) or mean prediction (regression) of the individual trees. Random decision forests correct for decision trees’ habit of overfitting to their training set.
from sklearn.ensemble import RandomForestClassifier RF_Cl=RandomForestClassifier(n_estimators=900) RF_Cl.fit(X_train,y_train) y_pred=RF_Cl.predict(X_test) accuracy_score(y_pred,y_test)
0.8329621380846325
print(classification_report(y_test, y_pred))
precision recall f1-score support
ham 0.83 0.84 0.83 225
spam 0.83 0.83 0.83 224
accuracy 0.83 449
macro avg 0.83 0.83 0.83 449
weighted avg 0.83 0.83 0.83 449
Classification of texts using TFidf
X_train, X_test, y_train, y_test = train_test_split(data['message'], data['label'], test_size = 0.3, random_state=0, shuffle = True, stratify=data['label']) vectorizer = TfidfVectorizer() X_train_vect = vectorizer.fit_transform(X_train) X_train_vect.shape
(1045, 3596)
Pipeline and Random_Forest classifier
clf_rf = Pipeline([('tfidf', TfidfVectorizer()), ('clf', RandomForestClassifier(n_estimators=100, n_jobs=-1))])
clf_rf.fit(X_train, y_train)
y_pred = clf_rf.predict(X_test)
confusion_matrix(y_test, y_pred)
array([[224, 1],
[ 24, 200]], dtype=int64)print(classification_report(y_test, y_pred))
precision recall f1-score support
ham 0.91 1.00 0.95 225
spam 1.00 0.91 0.95 224
accuracy 0.95 449
macro avg 0.95 0.95 0.95 449
weighted avg 0.95 0.95 0.95 449
accuracy_score(y_test, y_pred)
0.9510022271714922
clf_rf.predict(["Hey, whassup?"])
array(['ham'], dtype=object)
clf_rf.predict(["you have won tickets to the USA this summer."])
array(['ham'], dtype=object)
Support Vector Machine
clf_svc = Pipeline([('tfidf', TfidfVectorizer()), ('clf', SVC(C = 1000, gamma = 'auto'))])
clf_svc.fit(X_train, y_train)
y_pred = clf_svc.predict(X_test)
confusion_matrix(y_test, y_pred)
array([[221, 4],
[ 16, 208]], dtype=int64)print(classification_report(y_test, y_pred))
precision recall f1-score support
ham 0.93 0.98 0.96 225
spam 0.98 0.93 0.95 224
accuracy 0.96 449
macro avg 0.96 0.96 0.96 449
weighted avg 0.96 0.96 0.96 449
accuracy_score(y_test, y_pred)
0.955456570155902
clf_svc.predict(["Hey, whassup?"])
array(['ham'], dtype=object)
clf_svc.predict(["you have got free tickets to the USA this summer."])
array(['spam'], dtype=object)
Summary
- From above results we can conclude that
TFidfperforms better thanword embeddings, since even without hyperparamter tuning all models performed well on test data with accuracy above 93% in all models
1 Comment