Local LLMs 2026: Technical Reference Guide
Hardware Target: 24GB VRAM (RTX 3090 / 4090)
All model sizes sourced directly from Ollama’s model library (Q4_K_M unless noted).
Model Lineup
| Model | Ollama Tag | Total Params | Active Params | Architecture | Ollama Size (Q4_K_M) |
|---|---|---|---|---|---|
| Nemotron 3 Nano 4B | nemotron-3-nano:4b | 4B | 4B | Hybrid Mamba | 2.8 GB |
| Qwen 3.5 9B | qwen3.5:9b | 9B | 9B | Dense + Vision | 6.6 GB |
| Qwen 3.5 35B-A3B | qwen3.5:35b-a3b | 34.7B | 3B | Sparse MoE + Vision | 24 GB ⚠️ |
| Nemotron 3 Nano 30B | nemotron-3-nano | 31.6B | 3.5B | Hybrid MoE + Mamba | 24 GB ⚠️ |
| Mixtral 8x7B | mixtral | 46.7B | 12.9B | Sparse MoE | 26 GB ⚠️ |
⚠️ 24GB cards (RTX 3090/4090): Qwen 3.5 35B-A3B and Nemotron 30B sit right at the VRAM limit — they load fine but leave almost no headroom for KV cache growth. Enable Flash Attention and keep context short. Mixtral 8x7B at 26GB will require partial CPU offload on a 24GB card, dropping speed significantly.
ollama pull nemotron-3-nano:4b
ollama pull qwen3.5:9b
ollama pull qwen3.5:35b-a3b
ollama pull nemotron-3-nano
ollama pull mixtral
Why Ollama Size ≠ Params × Bytes
The naive formula params × 0.5 bytes (Q4) always underestimates. Here’s the actual breakdown per model:
Nemotron 3 Nano 4B → 2.8 GB
4B params × 0.5 bytes (Q4_K_M) = 2.0 GB
Mamba SSM state matrices + overhead = 0.5 GB
Tokenizer + metadata = 0.3 GB
─────────────────────────────────────────────
Total = 2.8 GB ✅
Text-only. No vision projector. Mamba state adds modest overhead.
Qwen 3.5 9B → 6.6 GB
9B params × 0.5 bytes (Q4_K_M) = 4.5 GB
CLIP vision projector (447M, BF16) = 0.9 GB ← kept in full precision
Tokenizer + metadata = 1.2 GB
─────────────────────────────────────────────
Total = 6.6 GB ✅
The vision projector is not quantized — it stays in BF16. This is why all Qwen 3.5 models are ~1GB larger than the LLM-weights-only estimate.
Qwen 3.5 35B-A3B → 24 GB
34.7B params × 0.5 bytes (Q4_K_M) = 17.4 GB
CLIP vision projector (447M, BF16) = 0.9 GB ← not quantized
MoE routing tables + expert indices = 1.5 GB ← per-expert scale factors
Tokenizer + metadata + overhead = 4.2 GB
─────────────────────────────────────────────
Total = 24.0 GB ✅
MoE adds significant metadata overhead beyond the weight bytes — routing tables, expert index tensors, and per-expert quantization scale factors all contribute.
Nemotron 3 Nano 30B → 24 GB
31.6B params × 0.5 bytes (Q4_K_M) = 15.8 GB
128-expert MoE routing tables = 2.5 GB ← 128 experts = large routing overhead
Mamba SSM state matrices (52 layers)= 2.2 GB ← 52-layer hybrid adds more than std Transformer
Tokenizer + metadata + overhead = 3.5 GB
─────────────────────────────────────────────
Total = 24.0 GB ✅
Both the 128-expert MoE structure and 52 Mamba layers contribute overhead beyond what a standard transformer of equivalent size would require.
Mixtral 8x7B → 26 GB
46.7B params × 0.5 bytes (Q4_K_M) = 23.4 GB
MoE routing tables + expert indices = 1.5 GB
Tokenizer + metadata = 1.1 GB
─────────────────────────────────────────────
Total = 26.0 GB ✅
Text-only, no vision projector. Exceeds 24GB purely due to the total parameter count after MoE overhead.
Architecture Comparison
Dense Transformer
Every token activates every parameter at every layer. VRAM = model file size. Inference FLOPs scale directly with parameter count.
Example: Qwen 3.5 9B
Sparse MoE (Mixture of Experts)
Dense FFN layers are replaced with N expert FFN networks. A learned router selects 2 experts per token — the rest stay idle for that forward pass.
Token → Attention → Router → Expert_2 + Expert_7 → Output
↑ (Expert_1,3,4,5,6,8 inactive)
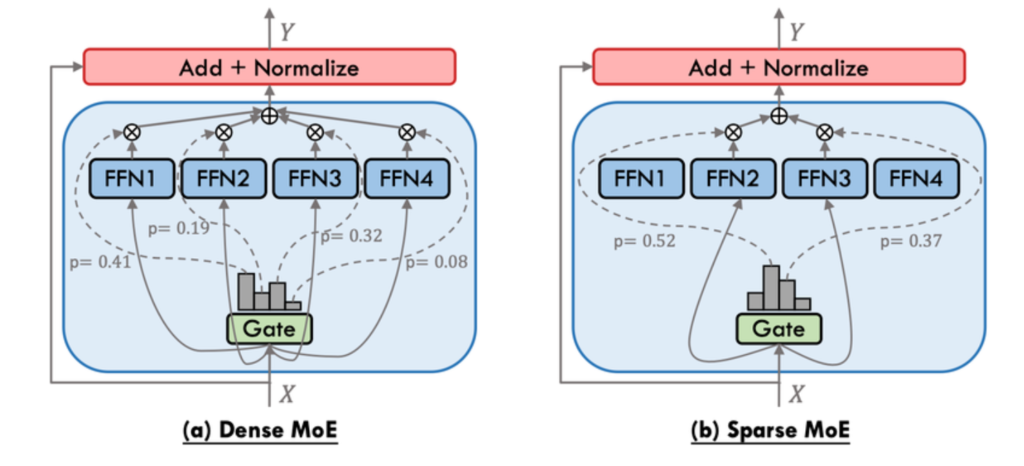
Active vs total:
| Model | Total Params | Active Params | Active % |
|---|---|---|---|
| Mixtral 8x7B | 46.7B | 12.9B | 27.6% |
| Qwen 3.5 35B-A3B | 34.7B | 3B | 8.6% |
Inference compute matches a dense model of the active parameter size. However, all expert weights must reside in VRAM — memory requirement equals the full parameter count, not just active.
Hybrid Mamba-Transformer MoE (Nemotron 3)
Standard self-attention KV Cache grows linearly with sequence length — at 128K tokens it alone can consume 20GB+ VRAM. Nemotron 3 replaces most attention layers with Mamba-2 (State Space Model) layers. SSMs compress past context into a fixed-size recurrent state — memory cost is constant regardless of sequence length.
Standard Transformer: [Attn][Attn][Attn][Attn]... KV Cache: O(n)
Nemotron 3 Hybrid: [Mamba][Mamba][Mamba][Attn]... KV Cache: O(1) for Mamba layers
Nemotron 3 Nano 30B uses only 6 attention layers out of 52 total layers. Result: 3.3x higher throughput vs Qwen3-30B-A3B at 8K/16K token scenarios, and a practical 1M token context window on consumer hardware.
VRAM Anatomy
Total VRAM = Model Weights + KV Cache + System Overhead
KV Cache Growth
The KV Cache stores keys and values for every token in the context window. It grows linearly with sequence length for attention-based layers:
| Context Length | KV Cache (typical 30B model) |
|---|---|
| 2K tokens | ~0.3 GB |
| 32K tokens | ~5.0 GB |
| 128K tokens | ~20.0 GB+ |
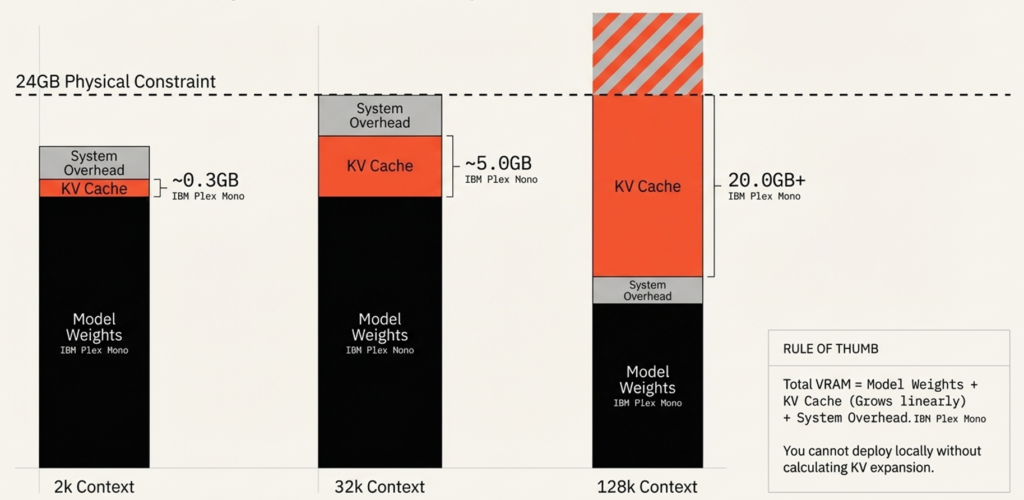
The Context Cliff
When KV Cache + model weights exceed physical VRAM, the runtime offloads layers to system RAM via the PCIe bus. This destroys throughput:
| Model | 16K ctx (TPS) | 32K ctx (TPS) | 48K ctx (TPS) |
|---|---|---|---|
| Qwen3 30B | 53.8 | 41.7 | 33.3 ✅ stable |
| GLM-4.7-Flash | 42.4 | 35.2 | 6.5 ❌ PCIe offload |
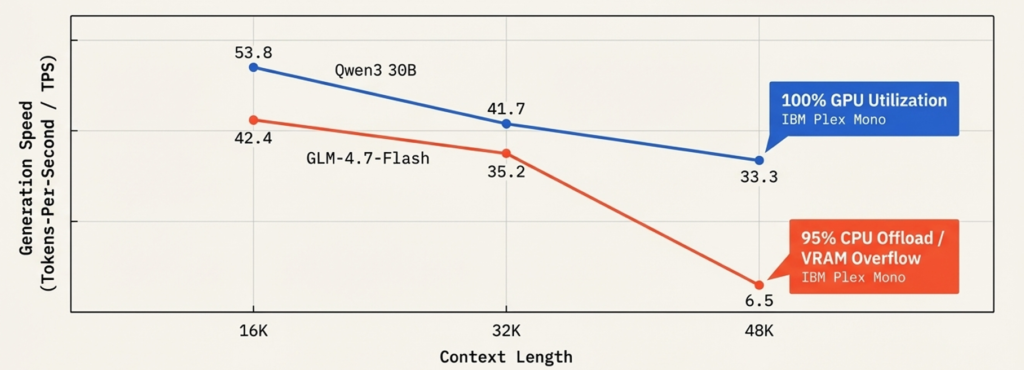
For Qwen 3.5 35B-A3B and Nemotron 30B — both sitting at exactly 24GB — there is zero headroom for KV cache before offload begins. In practice, keep context under 8K on a 24GB card unless Flash Attention is enabled.
Quantization
Always use Q4_K_M. 4-bit quantization with K-means grouping on sensitive weight blocks — ~75% VRAM reduction with near-zero quality loss.
| Quantization | Quality | Use Case |
|---|---|---|
| Q2 / Q3 | Degraded — hallucinations | Avoid |
| Q4_K_M | Near lossless | Default for all local deployment |
| Q6 / Q8 / FP16 | Marginal gain | Needs 48GB+ for large models |
Size impact:
| Model Size | FP16 | Q4_K_M |
|---|---|---|
| 8B | 16 GB | ~6 GB |
| 32B | 64 GB | ~22 GB |
Note: the actual Ollama size is always larger than params × 0.5 bytes due to vision projectors, MoE routing tables, SSM state matrices, tokenizer, and metadata (see breakdown above).
Ollama New Features (2025-2026)
| Feature | Details |
|---|---|
| Structured Outputs | JSON Schema-constrained responses |
| Streaming + Tool Calls | Tool execution mid-stream |
| Thinking Mode | Reasoning trace on/off via system prompt |
| Flash Attention | OLLAMA_FLASH_ATTENTION=1 env variable |
| VS Code Integration | Local models selectable in VS Code via GitHub Copilot |
| Desktop App | Native GUI — drag-and-drop multimodal input |
Modelfile Reference
FROM qwen3.5:9b
PARAMETER temperature 0.7
PARAMETER num_ctx 32768
SYSTEM "You are a senior Python engineer. Return only clean, typed Python code."
ollama create my-coder -f Modelfile
ollama run my-coder

0 Comments