Star Rating Prediction
Star Rating Prediction of Amazon Products Reviews

Objective
- In this notebook, we are going to predict the Ratings of Amazon products reviews by the help of given
reviewTextcolumn.
Natural Language Processing (NLP) is a sub-field of artificial intelligence that deals understanding and processing human language. In light of new advancements in machine learning, many organizations have begun applying natural language processing for translation, chatbots and candidate filtering.
Machine learning algorithms cannot work with raw text directly. Rather, the text must be converted into vectors of numbers. Then we use TF-IDF vectorizer approach. TF-IDF is a technique used for natural language processing that transforms text to feature vectors that can be used as input to the estimator.
Intro to Pandas
Pandas is a column-oriented data analysis API. It’s a great tool for handling and analyzing input data, and many ML frameworks support pandas data structures as inputs. Although a comprehensive introduction to the pandas API would span many pages, the core concepts are fairly straightforward, and we will present them below. For a more complete reference, the pandas docs site contains extensive documentation and many tutorials.
Intro to Numpy
Numpy is a library for the Python programming language, adding support for large, multi-dimensional arrays and matrices, along with a large collection of high-level mathematical functions to operate on these arrays. For a more complete reference, the numpy docs site contains extensive documentation and many tutorials.
Firstly install the pandas, numpy, scikit-learn library.
!pip install pandas !pip install numpy !pip install scikit-learn
import pandas as pd import numpy as np
Dataset is availablet here
df = pd.read_csv('https://raw.githubusercontent.com/laxmimerit/Amazon-Musical-Reviews-Rating-Dataset/master/Musical_instruments_reviews.csv', usecols = ['reviewText', 'overall'])
Pandas sample() is used to generate a sample random row or column from the function caller data frame.
df.sample(5)
| reviewText | overall | |
|---|---|---|
| 7959 | Cheap and good. Just what I needed. No issue… | 4.0 |
| 6048 | It sounds like it’s Behringer. Very fake, che… | 3.0 |
| 1596 | I already had the nickel finished version (whi… | 5.0 |
| 8796 | Well… it’s not really too expensive, but it … | 1.0 |
| 948 | The mic stand pick holder is a great way to ke… | 5.0 |
df['overall'].value_counts()
5.0 6938 4.0 2084 3.0 772 2.0 250 1.0 217 Name: overall, dtype: int64
df1 = pd.DataFrame() for val in df['overall'].unique(): temp = df[df['overall']==val].sample(217) df1 = df1.append(temp, ignore_index = True) df1
| reviewText | overall | |
|---|---|---|
| 0 | First off; let me start by saying I bought thi… | 5.0 |
| 1 | I purchased these cables for my Behringer 802 … | 5.0 |
| 2 | It looks fine but as other reviewers have poin… | 5.0 |
| 3 | I bought this for my 11 year old daughter to h… | 5.0 |
| 4 | I use this with my mobile DJ equipment and it … | 5.0 |
| … | … | … |
| 1080 | Bought this a while back just got around to in… | 1.0 |
| 1081 | DOA…no good, out of the box,plug it, nothing… | 1.0 |
| 1082 | I have had 2 of these tuners (you’d think I’d … | 1.0 |
| 1083 | These speakers worked great for 14 months. Las… | 1.0 |
| 1084 | This is a cheap stand and I was not surprised … | 1.0 |
1085 rows × 2 columns
Text Preprocessing
In natural language processing (NLP), text preprocessing is the practice of cleaning and preparing text data. NLTK and re are common Python libraries used to handle many text preprocessing tasks.
preprocess_kgptalkie python package is prepared by Kgptalkie
These are the some dependencies thay you have to install before using this preprocess_kgptalkie package.
!pip install spacy==2.2.3 !python -m spacy download en_core_web_sm !pip install beautifulsoup4==4.9.1 !pip install textblob==0.15.3
Importing preprocess_kgptalkie python package and also regular expression(re).
import preprocess_kgptalkie as ps import re
Defining get_clean function which is taking argument as ‘Reviews’ column then after perform some steps:
"""
Step 1: Lowering the letter then after replacing backward slash from nothing and underscore from space.
Step 2: Remove emails from the Reviews column.
Step 3: Removing html tags from the Reviews column.
Step 4: Removing special character.
Step 5: If you have multiple repeated character then it converted into single character and make meaningful.
E.g. x = 'lllooooovvveeee youuuu'
x = re.sub("(.)\\1{2,}", "\\1", x)
print(x)
-------
love you
"""
!pip install git+https://github.com/laxmimerit/preprocess_kgptalkie.git
Collecting git+https://github.com/laxmimerit/preprocess_kgptalkie.git Cloning https://github.com/laxmimerit/preprocess_kgptalkie.git to c:\users\mdezaj~1\appdata\local\temp\pip-req-build-5g7bbg9w Requirement already satisfied (use --upgrade to upgrade): preprocess-kgptalkie==0.0.5 from git+https://github.com/laxmimerit/preprocess_kgptalkie.git in c:\users\md ezajul hassan\appdata\local\programs\python\python37\lib\site-packages
You are using pip version 19.0.3, however version 20.2.2 is available. You should consider upgrading via the 'python -m pip install --upgrade pip' command.
def get_clean(x):
x = str(x).lower().replace('\\', '').replace('_', ' ')
x = ps.cont_exp(x)
x = ps.remove_emails(x)
x = ps.remove_urls(x)
x = ps.remove_html_tags(x)
x = ps.remove_accented_chars(x)
x = ps.remove_special_chars(x)
x = re.sub("(.)\\1{2,}", "\\1", x)
return x
df['reviewText'] = df['reviewText'].apply(lambda x: get_clean(x))
df.head()
| reviewText | overall | |
|---|---|---|
| 0 | not much to write about here but it does exact… | 5.0 |
| 1 | the product does exactly as it should and is q… | 5.0 |
| 2 | the primary job of this device is to block the… | 5.0 |
| 3 | nice windscreen protects my mxl mic and preven… | 5.0 |
| 4 | this pop filter is great it looks and performs… | 5.0 |
TF-IDF Vectorizer

Some semantic information is preserved as uncommon words are given more importance than common words in TF-IDF.
E.g. 'She is beautiful', Here 'beautiful will have more importance than 'she' or 'is'.
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.model_selection import train_test_split from sklearn.svm import LinearSVC from sklearn.metrics import classification_report
tfidf = TfidfVectorizer(max_features=20000, ngram_range=(1,5), analyzer='char')
X = tfidf.fit_transform(df['reviewText']) y = df['overall']
X.shape, y.shape
((10261, 20000), (10261,))
Here, spliting the dataset into x and y column having 20% is for testing and 80% for training purpose.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
X_train.shape
(8208, 20000)
Support Vector Machine
Definition
SVM is a supervised machine learning algorithm which can be used for classification or regression problems.It uses a technique called the kernel trick to transform your data and then based on these transformations it finds an optimal boundary between the possible outputs.
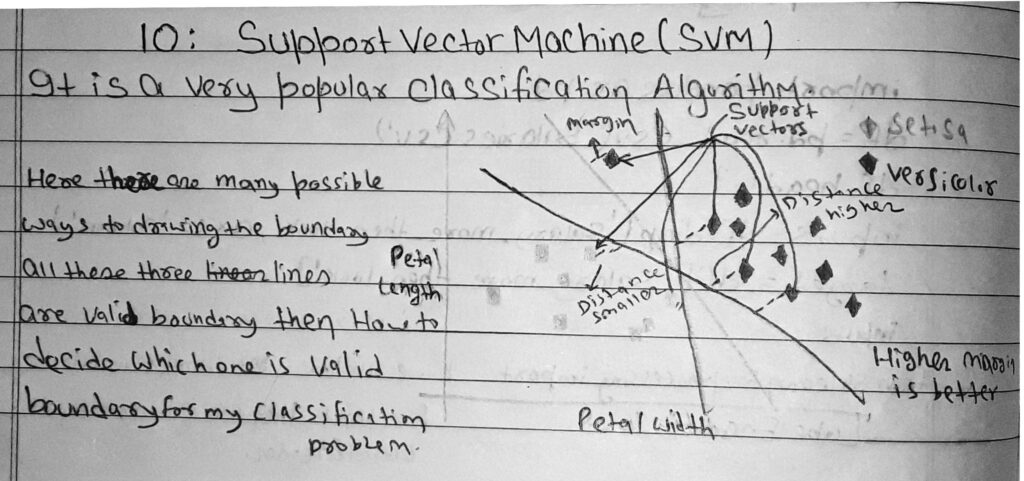
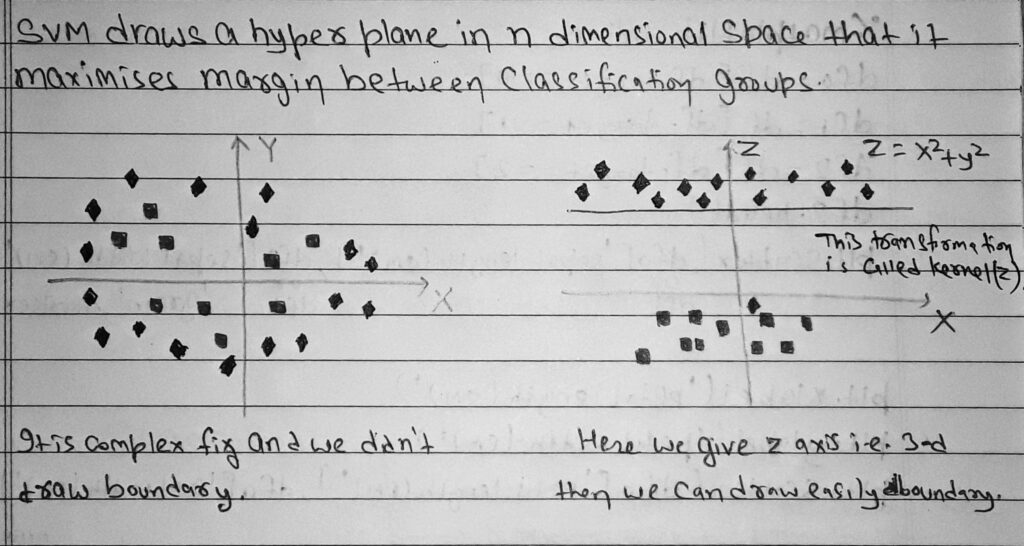
The objective of a Linear SVC (Support Vector Classifier) is to fit to the data you provide, returning a “best fit” hyperplane that divides, or categorizes, your data. From there, after getting the hyperplane, you can then feed some features to your classifier to see what the “predicted” class is.
clf = LinearSVC(C = 20, class_weight='balanced') clf.fit(X_train, y_train)
c:\users\md ezajul hassan\appdata\local\programs\python\python37\lib\site-packages\sklearn\svm\_base.py:977: ConvergenceWarning: Liblinear failed to converge, increase the number of iterations. "the number of iterations.", ConvergenceWarning)
LinearSVC(C=20, class_weight='balanced')
y_pred = clf.predict(X_test)
The classification report shows a representation of the main classification metrics on a per-class basis. This gives a deeper intuition of the classifier behavior over global accuracy which can mask functional weaknesses in one class of a multiclass problem.
print(classification_report(y_test, y_pred))
precision recall f1-score support
1.0 0.31 0.21 0.25 39
2.0 0.18 0.11 0.13 55
3.0 0.23 0.27 0.25 134
4.0 0.34 0.33 0.34 451
5.0 0.77 0.78 0.78 1374
accuracy 0.62 2053
macro avg 0.37 0.34 0.35 2053
weighted avg 0.61 0.62 0.62 2053
x = 'this product is really bad. i do not like it' x = get_clean(x) vec = tfidf.transform([x]) clf.predict(vec)
array([1.])
x = 'this product is really good. thanks a lot for speedy delivery' x = get_clean(x) vec = tfidf.transform([x]) clf.predict(vec)
array([5.])
Conclusion:
- Firstly, We have loaded the amazon musical reviews rating dataset using pandas dataframe.
- Then define get_clean() function and removed unwanted emails, URLs, Html tags and special character.
- Convert the text into vectors with the help of the TF-IDF Vectorizer.
- After that use a linear vector machine classifier algorithm.
- Finally, we have fit the model on the LinearSVC classifier for categorical classification and predict the rating on real data.
- By the hep of these steps, we got 62% accuracy.
0 Comments