Corrective RAG (CRAG) (Yan et al., 2024) adds a self-correction step to RAG. After retrieval, an LLM grades whether the documents can actually answer the question. If they can, it writes the answer. If they cannot, it rewrites the query and falls back to web search before answering. A single retry cycle prevents infinite loops.
In this blog, we build on the `retrieve_docs` and `web_search` tools from earlier in the series.
Prerequisites: the scripts/my_tools.py tools from RAG Data Retrieval and Re-Ranking. Ollama running with qwen3, plus the packages below.
pip install -U langgraph langchain-ollama langchain-core pydantic ddgs
ollama pull qwen3State and Setup
The state tracks the retrieved documents, the graded relevance, and the rewritten query alongside the message list.
from typing_extensions import TypedDict, Annotated
import operator, os
from langgraph.graph import StateGraph, START, END
from langchain_ollama import ChatOllama
from langchain_core.messages import HumanMessage, SystemMessage
from pydantic import BaseModel, Field
from scripts import my_tools
llm = ChatOllama(model="qwen3", base_url="http://localhost:11434")
class AgentState(TypedDict):
messages: Annotated[list, operator.add]
retrieved_docs: str
is_relevant: bool
rewritten_query: strRetrieve Node
The first node fetches documents from the vector store using the user's question.
def retrieve_node(state: AgentState):
user_question = state['messages'][-1].content
result = my_tools.retrieve_docs.invoke({'query': user_question, 'k': 5})
with open('debug_logs/crag_retrieved_docs.md', 'w', encoding='utf-8') as f:
f.write(f"Query: {user_question}\n\n")
f.write(result)
return {'retrieved_docs': result}Document Grading
A structured-output grader returns a boolean plus its reasoning. This is the heart of the "corrective" step.
class GradeDecision(BaseModel):
is_relevant: bool = Field(description="True if documents are relevant to answer the question, False if irrelevant")
reasoning: str = Field(description="Brief explanation of why documents are relevant or not.")
def grade_node(state: AgentState):
llm_structured = llm.with_structured_output(GradeDecision)
user_question = state['messages'][-1].content
retrieved_docs = state.get('retrieved_docs', '')
prompt = f"""You are a document relevance grader.
TASK: Evaluate if the retrieved documents are relevant to answer the user's question.
USER QUESTION: {user_question}
RETRIEVED DOCUMENTS:
{retrieved_docs}
GRADING CRITERIA:
- is_relevant = True: If documents contain information that can answer the question
- is_relevant = False: If documents are completely irrelevant or off-topic"""
response = llm_structured.invoke(prompt)
print(f"[GRADE] Relevant: {response.is_relevant}\nReasoning: {response.reasoning}")
return {'is_relevant': response.is_relevant}Rewrite and Web-Search Nodes

When grading fails, the rewrite node sharpens the query with financial keywords and the web-search node runs it through DuckDuckGo.
def rewrite_query_node(state: AgentState):
user_question = state['messages'][-1].content
prompt = f"""You are a query rewriting expert.
TASK: Rewrite the user's question to make it more specific and targeted for document retrieval.
ORIGINAL QUESTION: {user_question}
INSTRUCTIONS:
- Make the query more specific with keywords
- Add relevant financial terms (revenue, profit, earnings, etc.)
- Include company names, years, quarters if mentioned
Output ONLY the rewritten query, nothing else."""
rewritten_query = llm.invoke(prompt).content.strip()
print(f"[REWRITE] New: {rewritten_query}")
return {'rewritten_query': rewritten_query}
def web_search_node(state: AgentState):
user_question = state['messages'][-1].content
rewritten_query = state.get("rewritten_query", user_question)
result = my_tools.web_search.invoke({'query': rewritten_query})
with open('debug_logs/crag_retry_websearch_docs.md', 'w', encoding='utf-8') as f:
f.write(f"Rewritten Query: {rewritten_query}\n\n")
f.write(result)
return {'retrieved_docs': result}Answer Node and Router
The answer node writes a detailed, cited response from whatever documents are in state, vector-store or web. The router chooses between answering and rewriting based on the grade.
def answer_node(state: AgentState):
user_question = state['messages'][-1].content
retrieved_docs = state.get('retrieved_docs', '')
prompt = f"""You are an expert financial analyst.
TASK: Provide a detailed answer (200-300 words) using the retrieved documents.
Use MARKDOWN, inline citations [1], [2], and a References section at the end.
User Question: {user_question}
Retrieved Documents:
{retrieved_docs}"""
response = llm.invoke(prompt)
return {'messages': [response]}
def should_rewrite(state: AgentState):
if state.get('is_relevant', True):
print("[ROUTER] Document is relevant - proceeding to answer")
return "answer"
else:
print("[ROUTER] Documents are not relevant - rewriting the user query")
return 'rewrite'Building the Graph
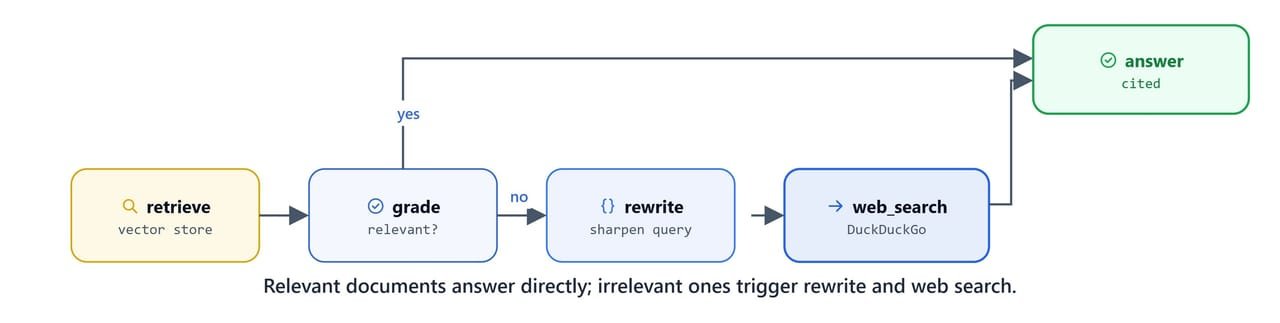
The conditional edge after grading branches to either answer or the rewrite → web_search → answer correction path.
def create_crag_agent():
builder = StateGraph(AgentState)
builder.add_node('retriever', retrieve_node)
builder.add_node('grade', grade_node)
builder.add_node('rewrite', rewrite_query_node)
builder.add_node('web_search', web_search_node)
builder.add_node('answer', answer_node)
builder.add_edge(START, 'retriever')
builder.add_edge('retriever', 'grade')
builder.add_conditional_edges('grade', should_rewrite, ['rewrite', 'answer'])
builder.add_edge('rewrite', 'web_search')
builder.add_edge('web_search', 'answer')
builder.add_edge('answer', END)
return builder.compile()
agent = create_crag_agent()Testing CRAG
When the documents are present, the grader passes and the agent answers directly:
query = "what is amazon's revenue in 2023?"
result = agent.invoke({'messages': [HumanMessage(query)]})[RETRIEVE NODE] Fetching documents
[TOOL] retrieve_docs called
[QUERY] what is amazon's revenue in 2023?
[RETRIEVED] 5 documents
[GRADE] Relevant: True
Reasoning: Documents 3 and 4 explicitly state Amazon's consolidated net sales (revenue) for 2023 as $574,785 million, directly answering the question.
[ROUTER] Document is relevant - proceeding to answerFor a company not in the vector store (Tesla), retrieval finds nothing. The grader marks it irrelevant, and CRAG corrects by rewriting the query and searching the web:
query = "what is Tesla revenue in 2023?"
result = agent.invoke({'messages': [HumanMessage(query)]})[RETRIEVE NODE] Fetching documents
[TOOL] retrieve_docs called
[QUERY] what is Tesla revenue in 2023?
Either No doc or keywords found!
[RETRIEVED] 0 documents
[GRADE] Relevant: False
Reasoning: No documents were retrieved to answer the question about Tesla's 2023 revenue.
[ROUTER] Documents are not relevant - rewriting the user query
[REWRITE] New: What is Tesla Inc.'s annual revenue for 2023 as reported in its 2023 annual financial report?Here, we can see CRAG catch the empty retrieval, mark it irrelevant, and reroute to a rewritten web search.
Warning
Web-sourced answers can include figures the model assembled from general knowledge rather than the cited page. CRAG fills coverage gaps, but always treat web-fallback numbers as less authoritative than the filings in your vector store.
The next lesson, Reflexion Agentic RAG, replaces the single retry with an iterative draft-and-revise loop.
What You Built
In this blog, we built a Corrective RAG agent:
- Relevance grader: a structured-output
GradeDecisiondecides whether retrievals can answer the question - Query rewriter: sharpens weak queries with specific financial keywords
- Web-search fallback: DuckDuckGo fills gaps the vector store cannot
- Branching router:
should_rewritesends relevant docs straight to the answer, irrelevant ones to correction - Single retry cycle:
retriever → grade → rewrite → web_search → answeravoids infinite loops
This is how corrective RAG works. It turns a fragile RAG pipeline into one that detects its own failures and recovers from them.



