Reflexion (Shinn et al., 2023) makes an agent self-improve through iteration. It drafts an answer, spots what is missing, retrieves to fill those gaps, then revises. It repeats until the answer is complete or it hits a maximum number of iterations. Where CRAG does a single correction, Reflexion runs a true feedback loop.
In this blog, we use gpt-oss and build on the `retrieve_docs` tool from earlier in the series.
Prerequisites: the scripts/my_tools.py tools from RAG Data Retrieval and Re-Ranking. Ollama running with gpt-oss, plus the packages below.
pip install -U langgraph langchain-ollama langchain-core pydantic
ollama pull gpt-ossNote
gpt-oss is OpenAI's open-weight model, distributed under the Apache 2.0 license. We can swap in qwen3 by changing LLM_MODEL if we prefer.
Schemas and State
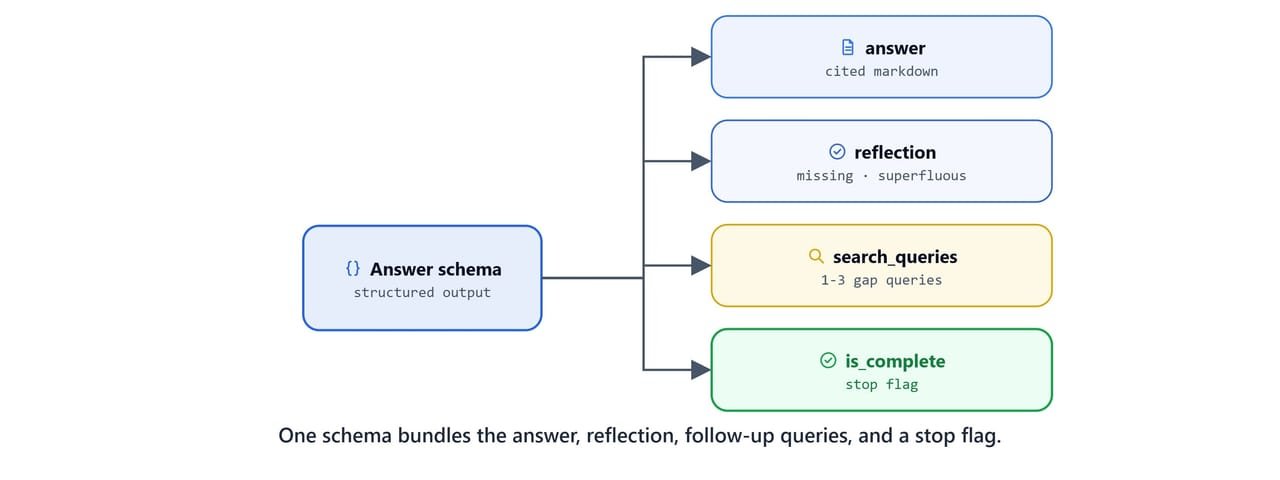
The Answer schema bundles the answer, a critical reflection, follow-up search queries, and a completion flag. So a single structured call produces everything the loop needs.
from typing import List
from langgraph.graph import StateGraph, START, END
from langchain_ollama import ChatOllama
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
from pydantic import BaseModel, Field
from typing_extensions import TypedDict, Annotated
import operator, os
from scripts import my_tools
BASE_URL = "http://localhost:11434"
LLM_MODEL = "gpt-oss"
MAX_ITERATIONS = 3
llm = ChatOllama(model=LLM_MODEL, base_url=BASE_URL)
class Reflection(BaseModel):
"""Critique of current answer"""
missing: str = Field(description="What critical information is missing or incomplete")
superfluous: str = Field(description="What information is unnecessary or redundant")
class Answer(BaseModel):
"""Answer with inline citation, reflection and search queries"""
answer: str = Field(description="Detailed answer with inline citation [1], [2] with reference list at the end")
reflection: Reflection = Field(description="Critical reflection on the answer")
search_queries: List[str] = Field(default_factory=list, description="1-3 search queries if more information needed, empty if complete")
is_complete: bool = Field(default=False, description="True if answer is complete and no more searches needed")
class AgentState(TypedDict):
messages: Annotated[List, operator.add]
iteration_count: int
retrieved_docs: str
search_queries: List[str]
is_complete: boolDraft Node
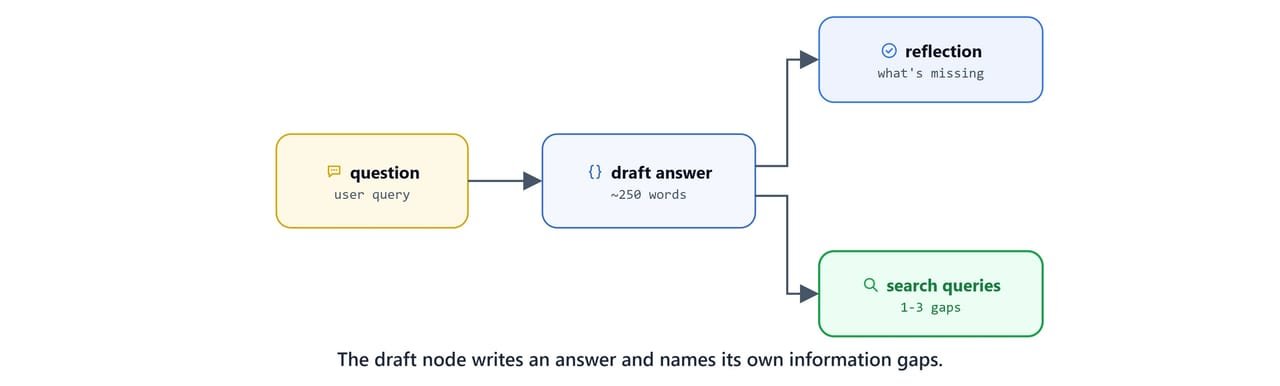
The draft node produces an initial answer plus a self-critique and the queries needed to fill the gaps.
def draft_node(state: AgentState):
llm_structured = llm.with_structured_output(Answer)
system_prompt = """You are an expert financial document researcher.
TASK:
1. Provide detailed answer (~250 words) to user's question
2. Use Markdown formatting (headings, bullets, tables, bold)
3. Reflect critically: identify missing and superfluous information
4. Generate 1-3 specific search queries to retrieve missing information"""
messages = [SystemMessage(system_prompt)] + state['messages']
response = llm_structured.invoke(messages)
text_response = f"""
**Answer**: {response.answer}\n\n
**Reflection** - Missing: {response.reflection.missing}\n\n
**Reflection** - Superfluous: {response.reflection.superfluous}\n\n
**Search Queries**: {','.join(response.search_queries)}"""
print(f"[DRAFT] Generated answer with {len(response.search_queries)}")
return {
'messages': [AIMessage(text_response)],
'iteration_count': 1,
'search_queries': response.search_queries
}Retrieve Node
The retrieve node runs every pending search query through the retrieval tool and combines the results.
def retrieve_node(state: AgentState):
search_queries = state.get('search_queries', [])
if not search_queries:
return {'retrieved_docs': 'No document is retrieved as there is no search query.'}
all_retrieved_text = []
for idx, query in enumerate(search_queries, 1):
print(f"[RETRIEVE] {idx} Query: {query}")
result = my_tools.retrieve_docs.invoke({'query': query, 'k': 3})
all_retrieved_text.append(f"\n---- Query {idx}: {query}\n\nResult:\n{result}")
combined_result = "\n\n".join(all_retrieved_text)
os.makedirs('debug_logs', exist_ok=True)
with open('debug_logs/reflexion_agentic_rag.md', 'w', encoding='utf-8') as f:
f.write(combined_result)
return {'retrieved_docs': combined_result}Revise Node
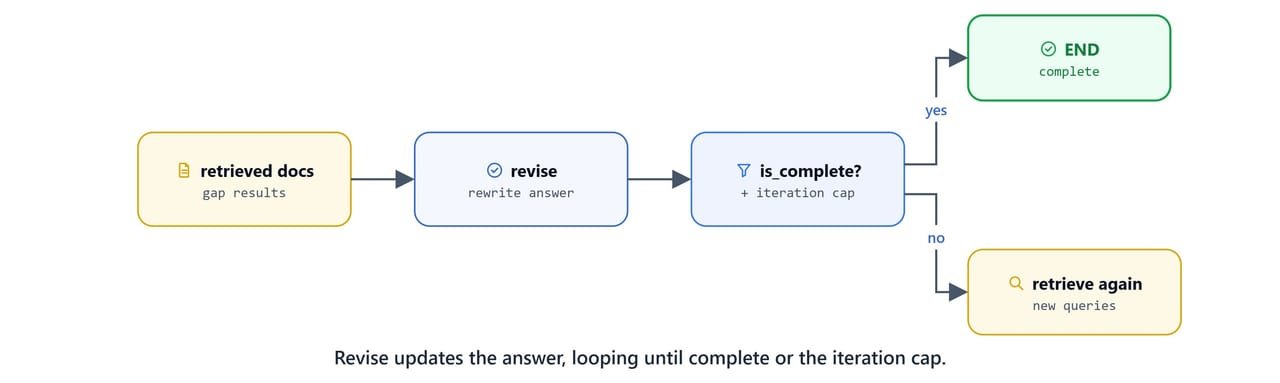
The revise node rewrites the answer using the new documents. It decides whether the answer is complete, and emits more queries if not. A safety check forces completion if the model claims incompleteness but gives no new queries.
def revise_node(state: AgentState):
print(f"[REVISE] Revise - Iteration {state.get('iteration_count', 1)}")
llm_structured = llm.with_structured_output(Answer)
system_prompt = """You are an expert financial document researcher.
TASK:
1. Write DETAILED answer (~250-300 words) with MARKDOWN formatting
2. Include inline citations [1], [2] and a reference list at the end
3. Critically reflect on what's missing or superfluous
4. Generate 2-3 SPECIFIC search queries if information is incomplete
DECISION LOGIC - ask yourself:
- Do I have complete quarterly breakdown? Segment-wise data? YoY comparisons?
- Do I have all metrics and all companies requested?
MANDATORY: If is_complete=false, you MUST provide 2-3 specific search_queries."""
query_prompt = f"""
Retrieved document:
{state.get('retrieved_docs', 'No doc found.')}
Revise your answer using these documents. Output JSON only data.
"""
messages = [SystemMessage(system_prompt)] + state['messages'] + [HumanMessage(query_prompt)]
response = llm_structured.invoke(messages)
if not response.is_complete and not response.search_queries:
print("[REVISE] WARNING - No queries but incomplete. Forcing completion.")
response.is_complete = True
print(f"[REVISE] Complete: {response.is_complete}")
text_response = f"""
**Answer**: {response.answer}\n\n
**Reflection** - Missing: {response.reflection.missing}\n\n
**Status** {'Complete' if response.is_complete else 'Needs more information'}"""
return {
'messages': [AIMessage(text_response)],
'iteration_count': state.get('iteration_count', 1) + 1,
'search_queries': response.search_queries,
'is_complete': response.is_complete
}Router and Graph
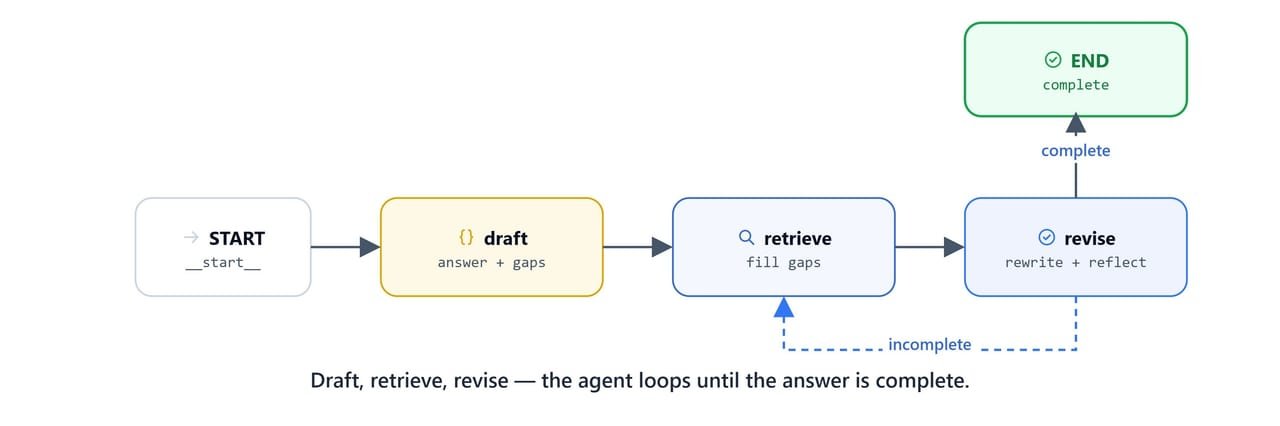
The router loops back to retrieval only while the answer is still incomplete. It also needs queries left and iterations to spare.
def should_continue(state: AgentState):
iteration_count = state.get('iteration_count', 0)
is_complete = state.get('is_complete', False)
search_queries = state.get('search_queries', [])
if is_complete or not search_queries or iteration_count >= MAX_ITERATIONS:
return END
print(f"[ROUTER] Iteration {iteration_count} - continue to retrieve")
return 'retrieve'The graph is a cycle: draft → retrieve → revise → (retrieve)* → END.
def create_reflexion_agent():
builder = StateGraph(AgentState)
builder.add_node('draft', draft_node)
builder.add_node('retrieve', retrieve_node)
builder.add_node('revise', revise_node)
builder.add_edge(START, 'draft')
builder.add_edge('draft', 'retrieve')
builder.add_edge('retrieve', 'revise')
builder.add_conditional_edges('revise', should_continue, ['retrieve', END])
return builder.compile()
agent = create_reflexion_agent()Testing Reflexion
A balance-sheet question drafts an answer, generates three gap-filling queries, retrieves, and revises:
query = "what is amazon's balance sheet in 2023?"
result = agent.invoke({'messages': [HumanMessage(query)]})[DRAFT] Generated answer with 3
[RETRIEVE] Fetching documents
[RETRIEVE] 1 Query: Amazon 2023 balance sheet figures 10-K
[RETRIEVE] 2 Query: Amazon total assets liabilities equity 2023
[RETRIEVE] 3 Query: Amazon 2023 annual report financial statements
[REVISE] Revise - Iteration 1
[REVISE] Complete: True
[ROUTER] iteration count: 2A comparison question fires several retrieval queries in one pass before it settles on a complete answer:
query = "Compare the Amazon's and Apple's revenue of 2024 Q1?"
result = agent.invoke({'messages': [HumanMessage(query)]})[DRAFT] Generated answer with 4
[RETRIEVE] 1 Query: Amazon Q1 2024 revenue $162.5B
[RETRIEVE] 2 Query: Apple fiscal Q1 2024 revenue $123.9B
[RETRIEVE] 3 Query: Amazon Q1 2024 earnings release
[RETRIEVE] 4 Query: Apple Q1 2024 earnings release
[REVISE] Revise - Iteration 1
[REVISE] Complete: TrueHere, we can see the agent draft, fire four queries, retrieve, and revise into a complete answer in one pass.
The next lesson, Self-RAG, checks the final answer for hallucination and usefulness rather than reflecting before retrieval.
What You Built
In this blog, we built a Reflexion agent:
- Unified
Answerschema: answer, reflection, follow-up queries, and a completion flag in one output - Draft node: produces an initial answer and names its own gaps
- Retrieve node: fetches documents for each gap-filling query
- Revise node: rewrites the answer and decides whether it is done, with a force-complete safeguard
- Bounded loop:
MAX_ITERATIONS = 3and theshould_continuerouter prevent runaway iteration
This is how Reflexion works. It turns a single-shot answer into a research process that keeps improving until nothing important is missing.



