DistilBERT – Smaller, faster, cheaper, lighter and ofcourse Distilled!
Sentiment Classification Using DistilBERT
Problem Statement
We will use the IMDB Movie Reviews Dataset, where based on the given review we have to classify the sentiments of that particular review like positive or negative.
The motivational BERT
BERT became an essential ingredient of many NLP deep learning pipelines. It is considered a milestone in NLP, as ResNet is in the computer vision field.
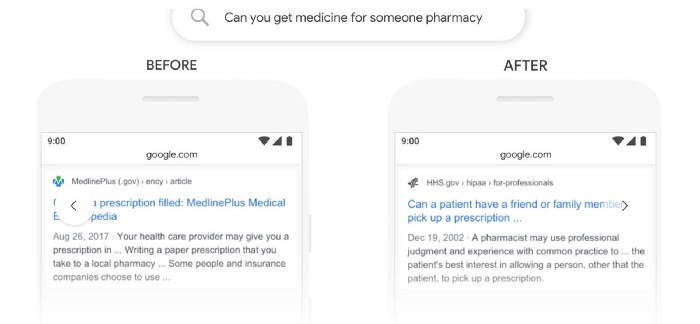
Google published an article “Understanding searches better than ever before” and positioned BERT as one of its most important updates to the searching algorithms in recent years. BERT is a language representation model with impressive accuracy for many NLP tasks. If you understand better what people ask, you give better answers. Google says 15% of the Google queries are never seen before. The real issue is not on what people ask. Instead, it is how many ways a question may be asked. Previously, Google search was keyword-based. But this is far from understanding what people ask or clarifying the ambiguity in human language. That is why Google has utilized BERT in its search engine. In the example below, BERT understands the intentions of “Can you get medicine for someone pharmacy” better and returns more relevant results.
But the only problem with BERT is its size..!!
BERT-base is a model contains 110M parameters. The larger variant BERT-large contains 340M parameters. It’s hard to deploy a model of such size into many environments with limited resources, such as a mobile or embedded systems.
What is DistilBERT
Distillation
Another interesting model compression method is a distillation — a technique that transfers the knowledge of a large “teacher” network to a smaller “student” network. The “student” network is trained to mimic the behaviors of the “teacher” network.
A version of this strategy has already been pioneered by Rich Caruana and his collaborators. In their important paper, they demonstrate convincingly that the knowledge acquired by a large ensemble of models can be transferred to a single small model. Geoffrey Hinton et al. showed this technique can be applied to neural networks in their paper called “Distilling the Knowledge in a Neural Network”.

Since then this approach was applied to different neural networks, and you probably heard of a BERT distillation called DistilBERT by HuggingFace.
Finally, October 2nd a paper on DistilBERT called DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter” emerged and was submitted at NeurIPS 2019.
DistilBERT is a smaller language model, trained from the supervision of BERT in which authors removed the token-type embeddings and the pooler (used for the next sentence classification task) and kept the rest of the architecture identical while reducing the numbers of layers by a factor of two.
BERT is designed to pre-train deep bidirectional representations from the unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be finetuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications.
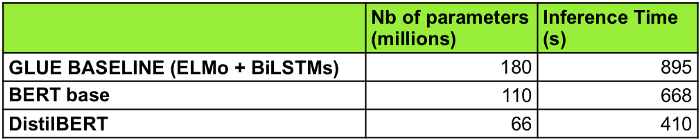
DistilBERT is a small, fast, cheap, and light Transformer model trained by distilling Bert base. It has 40% less parameters than bert-base-uncased, runs 60% faster while preserving over 95% of Bert’s performances as measured on the GLUE language understanding benchmark.

In terms of inference time, DistilBERT is more than 60% faster and smaller than BERT and 120% faster and smaller than ELMo+BiLSTM.

Why DistilBERT
- Accurate as much as Original BERT Model
- 60% faster
- 40% fewer parameters
- It can run on CPU
Additional Reading
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Video Lecture: BERT NLP Tutorial 1- Introduction | BERT Machine Learning | KGP Talkie
Ref BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
https://arxiv.org/abs/1810.04805
Understanding searches better than ever before:
https://www.blog.google/products/search/search-language-understanding-bert/
Good Resource to Read More About the BERT:
http://jalammar.github.io/illustrated-bert/
Visual Guide to Using BERT:
http://jalammar.github.io/a-visual-guide-to-using-bert-for-the-first-time/
What is ktrain
ktrain is a library to help build, train, debug, and deploy neural networks in the deep learning software framework, Keras.
ktrain uses tf.keras in TensorFlow instead of standalone Keras. Inspired by the fastai library, with only a few lines of code, ktrain allows you to easily:
- estimate an optimal learning rate for your model given your data using a learning rate finder
- employ learning rate schedules such as the triangular learning rate policy, 1cycle policy, and SGDR to more effectively train your model
- employ fast and easy-to-use pre-canned models for both text classification (e.g., NBSVM, fastText, GRU with pre-trained word embeddings) and image classification (e.g., ResNet, Wide Residual Networks, Inception)
- load and preprocess text and image data from a variety of formats
- inspect data points that were misclassified to help improve your model
- leverage a simple prediction API for saving and deploying both models and data-preprocessing steps to make predictions on new raw data
ktrain GitHub: https://github.com/amaiya/ktrain
Notebook Setup
!pip install ktrain
Downloading the dataset
!git clone https://github.com/laxmimerit/IMDB-Movie-Reviews-Large-Dataset-50k.git
Cloning into 'IMDB-Movie-Reviews-Large-Dataset-50k'... remote: Enumerating objects: 10, done. remote: Counting objects: 100% (10/10), done. remote: Compressing objects: 100% (8/8), done. remote: Total 10 (delta 1), reused 0 (delta 0), pack-reused 0 Unpacking objects: 100% (10/10), done.
Importing Libraries
import pandas as pd import numpy as np import ktrain from ktrain import text import tensorflow as tf
Loading dataset
#loading the training and testing dataset
data_test = pd.read_excel('/content/IMDB-Movie-Reviews-Large-Dataset-50k/test.xlsx', dtype= str)
data_train = pd.read_excel('/content/IMDB-Movie-Reviews-Large-Dataset-50k/train.xlsx', dtype = str)
#prining the five sample datapoints data_train.sample(5)
| Reviews | Sentiment | |
|---|---|---|
| 16715 | The sequel to the ever popular Cinderella stor… | pos |
| 11207 | Excellent pirate entertainment! It has all the… | pos |
| 12609 | The Underground Comedy movie is perhaps one of… | neg |
| 10685 | My cable TV has what’s called the Arts channel… | pos |
| 1633 | This movie was terrible. Throughout the whole … | neg |
#printing the available text classifiers models text.print_text_classifiers()
fasttext: a fastText-like model [http://arxiv.org/pdf/1607.01759.pdf] logreg: logistic regression using a trainable Embedding layer nbsvm: NBSVM model [http://www.aclweb.org/anthology/P12-2018] bigru: Bidirectional GRU with pretrained fasttext word vectors [https://fasttext.cc/docs/en/crawl-vectors.html] standard_gru: simple 2-layer GRU with randomly initialized embeddings bert: Bidirectional Encoder Representations from Transformers (BERT) [https://arxiv.org/abs/1810.04805] distilbert: distilled, smaller, and faster BERT from Hugging Face [https://arxiv.org/abs/1910.01108]
# text.texts_from_df return two tuples
# maxlen means it is considering that much words and rest are getting trucated
# preprocess_mode means tokenizing, embedding and transformation of text corpus(here it is considering distilbert model)
train, val, preproc) = text.texts_from_df(train_df=data_train, text_column='Reviews', label_columns='Sentiment',
val_df = data_test,
maxlen = 400,
preprocess_mode = 'distilbert')
preprocessing train... language: en train sequence lengths: mean : 234 95percentile : 598 99percentile : 913
Is Multi-Label? False preprocessing test... language: en test sequence lengths: mean : 234 95percentile : 598 99percentile : 913
Observation:
You can able to see that it is detecting language as an English.
Also, this is not multi-label classification
# name = "distilbert" means, here we are using distilbert model. model = text.text_classifier(name = 'distilbert', train_data = train, preproc=preproc)
Is Multi-Label? False maxlen is 400 done.
#here we have taken batch size as 6 as from the documentation it is recommend to use this with maxlen as 400
learner = ktrain.get_learner(model = model,
train_data = train,
val_data = val,
batch_size = 6)
#Essentially fit is a very basic training loop, whereas fit one cycle uses the one cycle policy callback learner.fit_onecycle(lr = 2e-5, epochs=2)
begin training using onecycle policy with max lr of 2e-05... Train for 4167 steps, validate for 782 steps Epoch 1/2 4167/4167 [==============================] - 3154s 757ms/step - loss: 0.2932 - accuracy: 0.8717 - val_loss: 0.1613 - val_accuracy: 0.9406 Epoch 2/2 4167/4167 [==============================] - 3131s 751ms/step - loss: 0.1552 - accuracy: 0.9440 - val_loss: 0.0623 - val_accuracy: 0.9836
<tensorflow.python.keras.callbacks.History at 0x7fe2fc067048>
#creating object for predictor model predictor = ktrain.get_predictor(learner.model, preproc)
#mounting with google drive
from google.colab import drive
drive.mount('/content/drive')
Go to this URL in a browser: https://accounts.google.com/o/oauth2/auth?client_id=947318989803-6bn6qk8qdgf4n4g3pfee6491hc0brc4i.apps.googleusercontent.com&redirect_uri=urn%3aietf%3awg%3aoauth%3a2.0%3aoob&response_type=code&scope=email%20https%3a%2f%2fwww.googleapis.com%2fauth%2fdocs.test%20https%3a%2f%2fwww.googleapis.com%2fauth%2fdrive%20https%3a%2f%2fwww.googleapis.com%2fauth%2fdrive.photos.readonly%20https%3a%2f%2fwww.googleapis.com%2fauth%2fpeopleapi.readonly Enter your authorization code: ·········· Mounted at /content/drive
#saving model
predictor.save('/content/drive/My Drive/distilbert')
data = ['this movie was really bad. acting was also bad. I will not watch again',
'the movie was really great. I will see it again', 'another great movie. must watch to everyone']
predictor.predict(data)
['neg', 'pos', 'pos']
Intepretation of above results :
‘this movie was really bad. acting was also bad. I will not watch again’ – neg
‘the movie was really great. I will see it again’ – pos
‘nother great movie. must watch to everyone’ – pos
#printing available classes predictor.get_classes()
['neg', 'pos']
#return_proba = True means it will give the prediction probabilty for each class predictor.predict(data, return_proba=True)
array([[0.9944576 , 0.00554235],
[0.00516187, 0.99483806],
[0.00479033, 0.99520963]], dtype=float32)Summary
- First, We have loaded the pre-loaded the dataset and process it using
pandasdataframe. - Thereafter we have used pre-trained model weights of
distilBERTon our dataset using kTrain library. - Then, we have found the best learning parameter and using that we have fit the model.
- Finally, using that model we have predicted our output.


0 Comments