Image Classification using pre-trained VGG-16 model
How to use Pre-trained VGG16 models to predict object

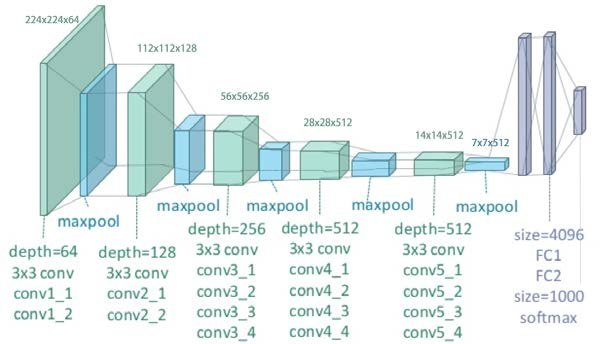
The VGG network architecture was introduced by Simonyan and Zisserman in their 2014 paper, Very Deep Convolutional Networks for Large Scale Image Recognition.
This network is characterized by its simplicity, using only 3×3 convolutional layers stacked on top of each other in increasing depth. Reducing volume size is handled by max pooling. Two fully-connected layers, each with 4,096 nodes are then followed by a softmax classifie
In 2014, 16 and 19 layer networks were considered very deep (although we now have the ResNet architecture which can be successfully trained at depths of 50-200 for ImageNet and over 1,000 for CIFAR-10)
Due to its depth and number of fully-connected nodes, VGG is over 533MB for VGG16 and 574MB for VGG19.
Architecture Explained:
- The input to the network is an image of dimensions (224, 224, 3).
- The first two layers have 64 channels of
3*3 filter size and same padding. Then after a max pool layer of stride (2, 2), two layers have convolution layers of 256 filter size and filter size (3, 3). - This followed by a max-pooling layer of stride (2, 2) which is same as the previous layer. Then there are
2 convolution layers of filter size (3, 3) and 256 filter. - After that, there are 2 sets of 3 convolution layer and a max pool layer. Each has
512 filters of (3, 3)size with the same padding. - This image is then passed to the stack of
two convolution layers. - In these convolution and max-pooling layers, the filters we use are of the size 3*3 instead of 11*11 in AlexNet and 7*7 in ZF-Net. In some of the layers, it also uses 1*1 pixel which is used to manipulate the number of input channels. There is a padding of 1-pixel (same padding) done after each convolution layer to prevent the spatial feature of the image.
- After the stack of convolution and max-pooling layer, we got a (7, 7, 512) feature map. We flatten this output to make it a (1, 25088) feature vector.
- After this there are 3 fully connected layer, the first layer takes input from the last feature vector and outputs a (1, 4096) vector, the second layer also outputs a vector of size (1, 4096) but the third layer output a 1000 channels for 1000 classes of ILSVRC challenge, then after the output of 3rd fully connected layer is passed to
softmax layer in order to normalize the classification vector.
After the output of classification vector top-5 categories for evaluation. All the hidden layers use ReLU as its activation function. ReLU is more computationally efficient because it results in faster learning and it also decreases the likelihood of vanishing gradient problem.
This model achieves 92.7% top-5 test accuracy on ImageNet dataset which contains 14 million images belonging to 1000 classes
Additional Reading
VGG Paper
https://arxiv.org/pdf/1409.1556.pdf
ILSVRC challenge
https://arxiv.org/pdf/1409.0575.pdf
Watch Full Lesson Here:
Importing Libraries
from tensorflow.keras.applications.vgg16 import VGG16, preprocess_input, decode_predictions from tensorflow.keras.preprocessing.image import load_img, img_to_array import os
#creating an object for VGG16 model(pre-trained) model = VGG16()
Downloading data from https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg16_weights_tf_dim_ordering_tf_kernels.h5 553467904/553467096 [==============================] - 255s 0us/step
model.summary()
Model: "vgg16" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, 224, 224, 3)] 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 224, 224, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, 224, 224, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, 112, 112, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, 112, 112, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, 112, 112, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, 56, 56, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, 56, 56, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, 28, 28, 256) 0 _________________________________________________________________ block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160 _________________________________________________________________ block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ block4_pool (MaxPooling2D) (None, 14, 14, 512) 0 _________________________________________________________________ block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_pool (MaxPooling2D) (None, 7, 7, 512) 0 _________________________________________________________________ flatten (Flatten) (None, 25088) 0 _________________________________________________________________ fc1 (Dense) (None, 4096) 102764544 _________________________________________________________________ fc2 (Dense) (None, 4096) 16781312 _________________________________________________________________ predictions (Dense) (None, 1000) 4097000 ================================================================= Total params: 138,357,544 Trainable params: 138,357,544 Non-trainable params: 0 _________________________________________________________________
In the below steps, we are performing following activities :
- loading 8 sample images from the disk
- Converting the image to array and then reshaping it.
- After performig the above steps, we are pre-process it and then predicting the output.
- top=2 in decode_predictions() function means which we are taking top 2 probability values for the particular prediction.
#Here we are taking sample images and predicting the same images on top of pre-trained VGG16 model.
#top=2 in decode_predictions() function means which we are taking top 2 probability values for the particular prediction.
for file in os.listdir('sample'):
print(file)
full_path = 'sample/' + file
image = load_img(full_path, target_size=(224, 224))
image = img_to_array(image)
image = image.reshape((1, image.shape[0], image.shape[1], image.shape[2]))
image = preprocess_input(image)
y_pred = model.predict(image)
label = decode_predictions(y_pred, top = 2)
print(label)
print()
bottle1.jpeg
[[('n04557648', 'water_bottle', 0.6603951), ('n04560804', 'water_jug', 0.08577988)]]
bottle2.jpeg
[[('n04557648', 'water_bottle', 0.5169559), ('n04560804', 'water_jug', 0.2630159)]]
bottle3.jpeg
[[('n04557648', 'water_bottle', 0.88239855), ('n04560804', 'water_jug', 0.051655706)]]
monitor.jpeg
[[('n03782006', 'monitor', 0.46309018), ('n03179701', 'desk', 0.16822667)]]
mouse.jpeg
[[('n03793489', 'mouse', 0.37214068), ('n03657121', 'lens_cap', 0.1903602)]]
mug.jpeg
[[('n03063599', 'coffee_mug', 0.46725288), ('n03950228', 'pitcher', 0.1496518)]]
pen.jpeg
[[('n02783161', 'ballpoint', 0.6506707), ('n04116512', 'rubber_eraser', 0.12477029)]]
wallet.jpeg
[[('n04026417', 'purse', 0.530347), ('n04548362', 'wallet', 0.24484588)]]
Challenges Of VGG 16:
- It is very slow to train (the original VGG model was trained on Nvidia Titan GPU for 2-3 weeks).
- The size of VGG-16 trained imageNet weights is 528 MB. So, it takes quite a lot of disk space and bandwidth that makes it inefficient.


1 Comment