Phone Number, Email, Emoji Extraction in SpaCy for NLP
Text Extraction in SpaCy
spaCy is a free, open-source library for advanced Natural Language Processing (NLP) in Python.
If you’re working with a lot of text, you’ll eventually want to know more about it. For example, what’s it about? What do the words mean in context? Who is doing what to whom? What companies and products are mentioned? Which texts are similar to each other?
spaCy is designed specifically for production use and helps you build applications that process and “understand” large volumes of text. It can be used to build information extraction or natural language understanding systems, or to pre-process text for deep learning.
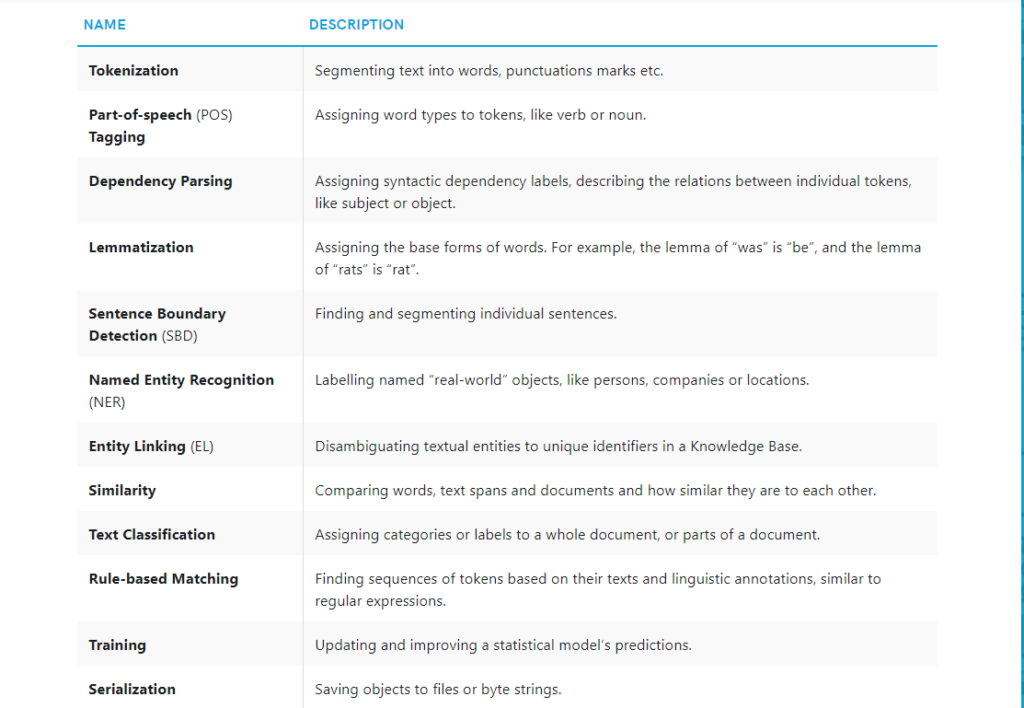
Below are some of spaCy’s features and capabilities. Some of them refer to linguistic concepts, while others are related to more general machine learning functionality.
spaCy installation
You can run the following commands:-
!pip install -U spacy
!pip install -U spacy-lookups-data
!python -m spacy download en_core_web_sm
You can check the first part of the blog here.
You can even watch the video of the first part
Check out the video of this blog
Using Linguistic Annotations
Let’s say you’re analyzing user comments and you want to find out what people are saying about Facebook. You want to start off by finding adjectives following “Facebook is” or “Facebook was”. This is obviously a very rudimentary solution, but it’ll be fast, and a great way to get an idea for what’s in your data. Your pattern could look like this:
[{"LOWER": "facebook"}, {"LEMMA": "be"}, {"POS": "ADV", "OP": "*"}, {"POS": "ADJ"}]
This translates to a token whose lowercase form matches “facebook” (like Facebook, facebook or FACEBOOK), followed by a token with the lemma “be” (for example, is, was, or ‘s), followed by an optional adverb, followed by an adjective.
This is the link for all the annotations-
https://spacy.io/api/annotation
Here we are importing the necessary libraries.
import spacy from spacy.matcher import Matcher from spacy.tokens import Span from spacy import displacy
spacy.load() loads a model.
nlp = spacy.load('en_core_web_sm')
matcher.add() adds a rule to the matcher, consisting of an ID key, one or more patterns, and a callback function to act on the matches. In our case the ID key is fb. The call back function is callback_method_fb(). The callback function will receive the arguments matcher, doc, i and matches. The matcher returns a list of (match_id, start, end) tuples. The match_id is the hash value of the string ID “fb”.
We have used the same pattern explained above.
matcher = Matcher(nlp.vocab)
matched_sents = []
pattern = [{"LOWER": "facebook"}, {"LEMMA": "be"}, {"POS": "ADV", "OP": "*"}, {"POS": "ADJ"}]
def callback_method_fb(matcher, doc, i, matches):
matched_id, start, end = matches[i]
span = doc[start:end]
sent = span.sent
match_ents = [{
'start':span.start_char - sent.start_char,
'end': span.end_char - sent.start_char,
'label': 'MATCH'
}]
matched_sents.append({'text': sent.text, 'ents':match_ents})
matcher.add("fb", callback_method_fb, pattern)
doc = nlp("I'd say that Facebook is evil. – Facebook is pretty cool, right?")
matches = matcher(doc)
matches
[(8017838677478259815, 4, 7), (8017838677478259815, 9, 13)]
We can see the matched sentences and their start and end positions.
matched_sents
[{'text': "I'd say that Facebook is evil.",
'ents': [{'start': 13, 'end': 29, 'label': 'MATCH'}]},
{'text': '– Facebook is pretty cool, right?',
'ents': [{'start': 2, 'end': 25, 'label': 'MATCH'}]}]displacy visualizes dependencies and entities in your browser or in a notebook. displaCy is able to detect whether you’re working in a Jupyter notebook, and will return markup that can be rendered in a cell straight away.
displacy.render(matched_sents, style='ent', manual = True)
I’d say that Facebook is evil MATCH .– Facebook is pretty cool MATCH , right?
Phone numbers
Phone numbers can have many different formats and matching them is often tricky. During tokenization, spaCy will leave sequences of numbers intact and only split on whitespace and punctuation. This means that your match pattern will have to look out for number sequences of a certain length, surrounded by specific punctuation – depending on the national conventions.
You want to match like this (123) 4567 8901 or (123) 4567-8901
[{"ORTH": "("}, {"SHAPE": "ddd"}, {"ORTH": ")"}, {"SHAPE": "dddd"}, {"ORTH": "-", "OP": "?"}, {"SHAPE": "dddd"}]
In this pattern we are looking for a opening bracket. Then we are matching a number with 3 digits. Then a closing bracket. Then a number with 4 digits. Then a dash which is optional. Lastly, a number with 4 digits.
pattern = [{"ORTH": "("}, {"SHAPE": "ddd"}, {"ORTH": ")"}, {"SHAPE": "dddd"}, {"ORTH": "-", "OP": "?"}, {"SHAPE": "dddd"}]
matcher = Matcher(nlp.vocab)
matcher.add("PhoneNumber", None, pattern)
doc = nlp("Call me at (123) 4560-7890")
print([t.text for t in doc])
['Call', 'me', 'at', '(', '123', ')', '4560', '-', '7890']
A match is found between 3rd to 9th position.
matches = matcher(doc) matches
[(7978097794922043545, 3, 9)]
We can get the matched number.
for match_id, start, end in matches:
span = doc[start:end]
print(span.text)
(123) 4560-7890
Email Address Matching
In this the pattern checks for one or more character from a-zA-Z0-9-_.. Then a @. Then again one or more character from a-zA-Z0-9-_.
pattern = [{"TEXT": {"REGEX": "[a-zA-Z0-9-_.]+@[a-zA-Z0-9-_.]+"}}]
matcher = Matcher(nlp.vocab)
matcher.add("Email", None, pattern)
text = "Email me at email2me@kgptalkie.com and talk.me@kgptalkie.com"
doc = nlp(text)
matches = matcher(doc)
matches
[(11010771136823990775, 3, 4), (11010771136823990775, 5, 6)]
for match_id, start, end in matches:
span = doc[start:end]
print(span.text)
email2me@kgptalkie.com talk.me@kgptalkie.com
Hashtags and emoji on social media
Social media posts, especially tweets, can be difficult to work with. They’re very short and often contain various emoji and hashtags. By only looking at the plain text, you’ll lose a lot of valuable semantic information.
Let’s say you’ve extracted a large sample of social media posts on a specific topic, for example posts mentioning a brand name or product. As the first step of your data exploration, you want to filter out posts containing certain emoji and use them to assign a general sentiment score, based on whether the expressed emotion is positive or negative, e.g. 😀 or 😞. You also want to find, merge and label hashtags like #MondayMotivation, to be able to ignore or analyze them later.
By default, spaCy’s tokenizer will split emoji into separate tokens. This means that you can create a pattern for one or more emoji tokens. Valid hashtags usually consist of a #, plus a sequence of ASCII characters with no whitespace, making them easy to match as well.
We have made a list of positive and negative emojis.
pos_emoji = ["😀", "😃", "😂", "🤣", "😊", "😍"] # Positive emoji neg_emoji = ["😞", "😠", "😩", "😢", "😭", "😒"] # Negative emoji pos_emoji
['😀', '😃', '😂', '🤣', '😊', '😍']
Now we will create a pattern for positive and negative emojis.
# Add patterns to match one or more emoji tokens
pos_patterns = [[{"ORTH": emoji}] for emoji in pos_emoji]
neg_patterns = [[{"ORTH": emoji}] for emoji in neg_emoji]
pos_patterns
[[{'ORTH': '😀'}],
[{'ORTH': '😃'}],
[{'ORTH': '😂'}],
[{'ORTH': '🤣'}],
[{'ORTH': '😊'}],
[{'ORTH': '😍'}]]neg_patterns
[[{'ORTH': '😞'}],
[{'ORTH': '😠'}],
[{'ORTH': '😩'}],
[{'ORTH': '😢'}],
[{'ORTH': '😭'}],
[{'ORTH': '😒'}]]We will write a function label_sentiment() which will be called after every match to label the sentiment of the emoji. If the sentiment is positive then we are adding 0.1 to doc.sentiment and if the sentiment is negative then we are subtracting 0.1 from doc.sentiment.
def label_sentiment(matcher, doc, i, matches):
match_id, start, end = matches[i]
if doc.vocab.strings[match_id] == 'HAPPY':
doc.sentiment += 0.1
elif doc.vocab.strings[match_id] == 'SAD':
doc.sentiment -= 0.1
Here with the HAPPY and SAD matchers we are also adding HASHTAG matcher to extract the hashtags. For hashtags we are going to match text which has atleast one ‘#’.
matcher = Matcher(nlp.vocab)
matcher.add("HAPPY", label_sentiment, *pos_patterns)
matcher.add('SAD', label_sentiment, *neg_patterns)
matcher.add('HASHTAG', None, [{'TEXT': '#'}, {'IS_ASCII': True}])
doc = nlp("Hello world 😀 #KGPTalkie")
matches = matcher(doc)
for match_id, start, end in matches:
string_id = doc.vocab.strings[match_id] # Look up string ID
span = doc[start:end]
print(string_id, span.text)
HAPPY 😀 HASHTAG #KGPTalkie
Efficient phrase matching
If you need to match large terminology lists, you can also use the PhraseMatcher and create Doc objects instead of token patterns, which is much more efficient overall. The Doc patterns can contain single or multiple tokens.
We are going to extract the names in terms from a document. We have made a pattern for the same.
from spacy.matcher import PhraseMatcher matcher = PhraseMatcher(nlp.vocab) terms = ['BARAC OBAMA', 'ANGELA MERKEL', 'WASHINGTON D.C.'] pattern = [nlp.make_doc(text) for text in terms] pattern
[BARAC OBAMA, ANGELA MERKEL, WASHINGTON D.C.]
This is our document.
matcher.add('term', None, *pattern)
doc = nlp("German Chancellor ANGELA MERKEL and US President BARAC OBAMA "
"converse in the Oval Office inside the White House in WASHINGTON D.C.")
doc
German Chancellor ANGELA MERKEL and US President BARAC OBAMA converse in the Oval Office inside the White House in WASHINGTON D.C.
We have found the matches.
matches = matcher(doc)
for match_id, start, end in matches:
span = doc[start:end]
print(span.text)
ANGELA MERKEL BARAC OBAMA WASHINGTON D.C.
matches
[(4519742297340331040, 2, 4), (4519742297340331040, 7, 9), (4519742297340331040, 19, 21)]
Custom Rule Based Entity Recognition
The EntityRuler is an exciting new component that lets you add named entities based on pattern dictionaries, and makes it easy to combine rule-based and statistical named entity recognition for even more powerful models.
Entity Patterns
Entity patterns are dictionaries with two keys: “label”, specifying the label to assign to the entity if the pattern is matched, and “pattern”, the match pattern. The entity ruler accepts two types of patterns:
- Phrase Pattern
{"label": "ORG", "pattern": "Apple"} - Token Pattern
{"label": "GPE", "pattern": [{"LOWER": "san"}, {"LOWER": "francisco"}]}
Using the entity ruler
The EntityRuler is a pipeline component that’s typically added via nlp.add_pipe. When the nlp object is called on a text, it will find matches in the doc and add them as entities to the doc.ents, using the specified pattern label as the entity label.
https://spacy.io/api/annotation#named-entities
We are importing EntityRuler from spacy.pipeline. Then we are loading a fresh model using spacy.load(). We have created a pattern which will label KGP Talkie as ORG and san francisco as GPE.
from spacy.pipeline import EntityRuler
nlp = spacy.load('en_core_web_sm')
ruler = EntityRuler(nlp)
patterns = [{"label": "ORG", "pattern": "KGP Talkie"},
{"label": "GPE", "pattern": [{"LOWER": "san"}, {"LOWER": "francisco"}]}]
patterns
[{'label': 'ORG', 'pattern': 'KGP Talkie'},
{'label': 'GPE', 'pattern': [{'LOWER': 'san'}, {'LOWER': 'francisco'}]}]ruler.add_patterns(patterns)
nlp.add_pipe(ruler)
doc = nlp("KGP Talkie is opening its first big office in San Francisco.")
doc
KGP Talkie is opening its first big office in San Francisco.
We can see that KGP Talkie and San Francisco are considered as entites.
for ent in doc.ents:
print(ent.text, ent.label_)
KGP Talkie PERSON first ORDINAL San Francisco GPE
Compared to using only regular expressions on raw text, spaCy’s rule-based matcher engines and components not only let you find the words and phrases you’re looking for – they also give you access to the tokens within the document and their relationships. This means you can easily access and analyze the surrounding tokens, merge spans into single tokens or add entries to the named entities.


1 Comment