Self-RAG (Asai et al., 2023) adds two quality gates after generation. It grades the retrieved documents, then generates an answer. Next it checks that answer for hallucinations (is it grounded?) and usefulness (does it address the query?). Failing either gate sends the flow back to regenerate, or to rewrite the query and retrieve again.
In this blog, we build on the `retrieve_docs` tool from earlier in the series. The nodes defined here live in scripts/nodes.py and are reused by the final lesson, Adaptive RAG.
Prerequisites: the scripts/my_tools.py tools from RAG Data Retrieval and Re-Ranking. Ollama running with qwen3, plus the packages below.
pip install -U langgraph langchain-ollama langchain-core pydantic
ollama pull qwen3Schemas and State
Four structured-output graders drive the decisions, each returning a simple 'yes'/'no' binary score.
from typing_extensions import TypedDict, Annotated
from typing import List
import os, operator
from langgraph.graph import StateGraph, START, END
from langchain_ollama import ChatOllama
from langchain_core.messages import HumanMessage, SystemMessage
from pydantic import BaseModel, Field
from scripts import my_tools
llm = ChatOllama(model="qwen3", base_url="http://localhost:11434", reasoning=True)
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documents."""
binary_score: str = Field(description="Documents are relevant to the query, 'yes' or 'no'")
class GradeHallucinations(BaseModel):
"""Binary score for hallucination present in generation answer."""
binary_score: str = Field(description="Answer is grounded with the facts for the query, 'yes' or 'no'")
class GradeAnswer(BaseModel):
"""Binary score to assess answer addresses query."""
binary_score: str = Field(description="Answer addresses the query, 'yes' or 'no'")
class SearchQueries(BaseModel):
"""Search queries for retrieving missing information."""
search_queries: list[str] = Field(description="1-3 search queries to retrieve the missing information.")
class AgentState(TypedDict):
messages: Annotated[list, operator.add]
retrieved_docs: str
rewritten_queries: List[str]A helper finds the latest human message, since the message list grows as the graph loops.
def get_latest_user_query(messages: list):
for message in reversed(messages):
if isinstance(message, HumanMessage):
return message.content
return messages[0].content if messages else ''Retrieve and Grade Documents
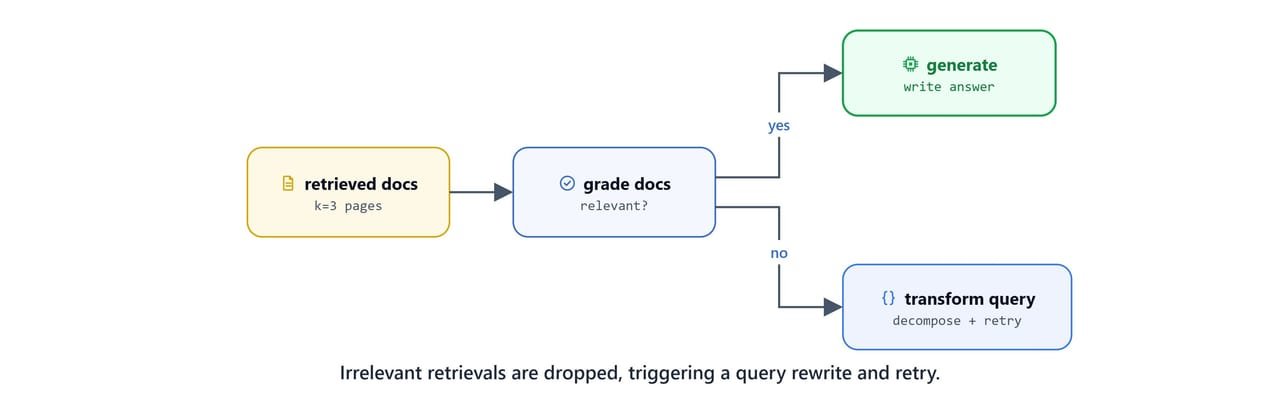
Retrieval honors rewritten queries when they exist. The grader filters out bad retrievals by emptying retrieved_docs on a "no" verdict. The router downstream reads that empty list as "transform the query."
def retrieve_node(state):
query = get_latest_user_query(state['messages'])
rewritten_queries = state.get('rewritten_queries', [])
queries_to_search = rewritten_queries if rewritten_queries else [query]
all_results = []
for idx, search_query in enumerate(queries_to_search, 1):
result = my_tools.retrieve_docs.invoke({'query': search_query, 'k': 3})
all_results.append(f"## Query {idx}: {search_query}\n\n### Retrieved Documents:\n{result}")
combined_result = "\n\n".join(all_results)
return {'retrieved_docs': combined_result}
def grade_documents_node(state):
query = get_latest_user_query(state['messages'])
documents = state.get('retrieved_docs', 'No document available!')
llm_structured = llm.with_structured_output(GradeDocuments)
system_prompt = """You are a grader assessing relevance of retrieved documents to a user query.
It does not need to be a stringent test. The goal is to filter out erroneous retrievals.
Give a binary score 'yes' or 'no' to indicate whether the document is relevant to the query."""
messages = [SystemMessage(system_prompt),
HumanMessage(f"Retrieved Document: {documents}\n\nUser query: {query}")]
response = llm_structured.invoke(messages)
print(f"[GRADE] Relevance: {response.binary_score}")
return {'retrieved_docs': documents} if response.binary_score == 'yes' else {'retrieved_docs': ''}Generate and Transform-Query Nodes
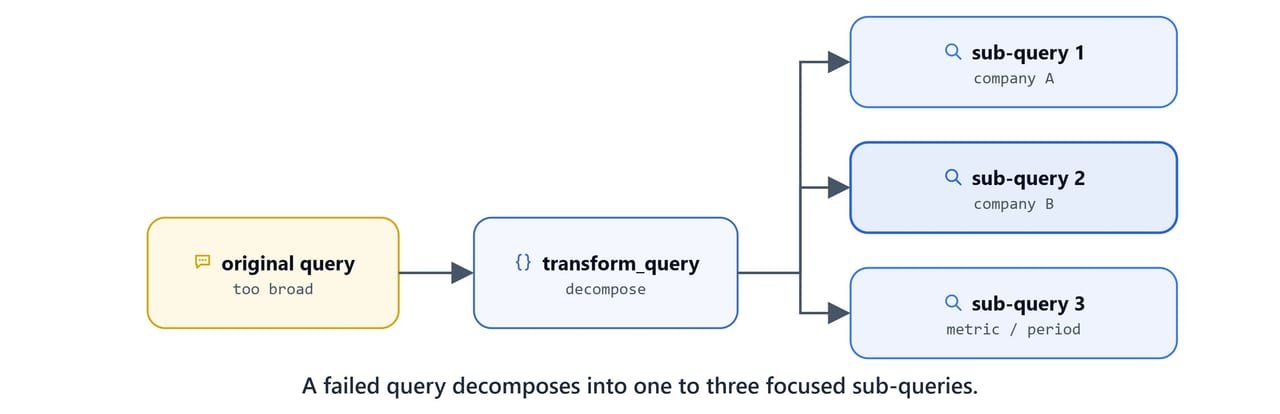
The generate node produces the cited Markdown answer. The transform-query node breaks the original question into focused sub-queries when retrieval fails. It also avoids queries it already tried.
def generate_node(state):
print("[GENERATE] Creating Answer")
query = get_latest_user_query(state['messages'])
documents = state.get('retrieved_docs', '')
system_prompt = """You are a financial document analyst providing detailed, accurate answers.
Write a comprehensive answer (200-300 words) in MARKDOWN with ## headings,
**bold**, bullet/numbered lists, and inline citations [1], [2].
Base your answer ONLY on the provided documents. End with a References list."""
messages = [SystemMessage(system_prompt),
HumanMessage(f"Retrieved Document: {documents}\n\nUser query: {query}")]
response = llm.invoke(messages)
return {'messages': [response]}
def transform_query_node(state):
query = get_latest_user_query(state['messages'])
rewritten_queries = state.get('rewritten_queries', [])
llm_structured = llm.with_structured_output(SearchQueries)
system_prompt = """You are a query re-writer that decomposes complex queries into focused search queries optimized for vectorstore retrieval.
DECOMPOSITION STRATEGY:
Break down the original query into 1-3 specific, focused queries where each targets:
- A single company, a specific time period, a specific metric, or a specific document section
GUIDELINES:
- Expand abbreviations (e.g., "rev" -> "revenue", "GOOGL" -> "Google")
- Make each query self-contained and specific (5-10 words each)
- Avoid repeating previously tried queries"""
query_context = f"Original Query: {query}"
if rewritten_queries:
query_context += "\n\n These queries have been already generated. do not generate same queries again.\n"
for idx, q in enumerate(rewritten_queries, 1):
query_context += f"Query {idx}: {q}\n\n"
query_context += "\n\nGenerate 1-3 focused search queries that decompose the original query."
response = llm_structured.invoke([SystemMessage(system_prompt), HumanMessage(query_context)])
print(f"New Search Queries: {response.search_queries}")
return {"rewritten_queries": response.search_queries}The Two Quality Gates
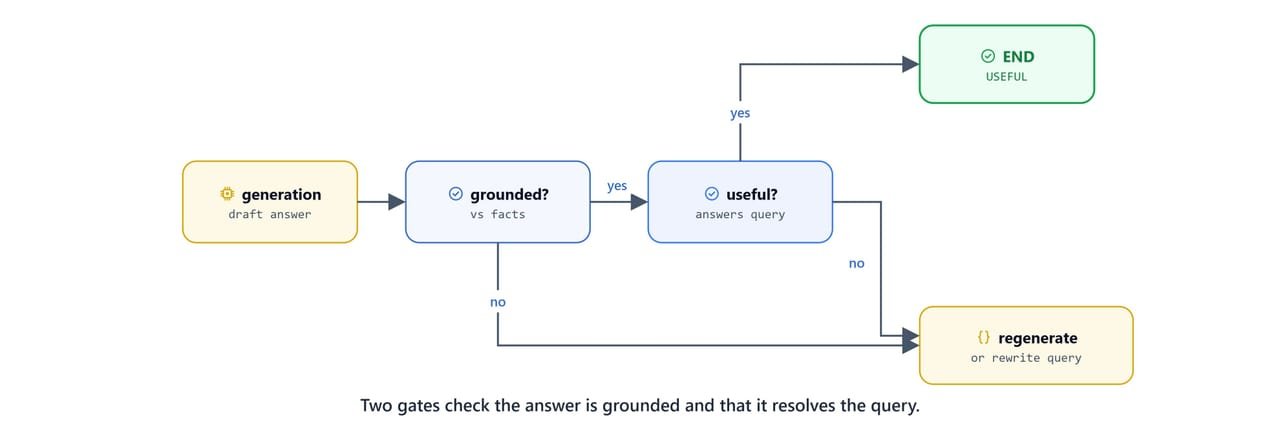
should_generate routes to transform_query when no relevant docs survived grading. check_answer_quality runs the hallucination grader first. If the answer is grounded, it checks usefulness. It ends on success, rewrites the query if the answer misses the point, or regenerates if the answer is ungrounded.
def should_generate(state):
retrieved_docs = state.get('retrieved_docs', '')
if not retrieved_docs or retrieved_docs.strip() == '':
print("[ROUTER] No relevant documents - transforming query")
return 'transform_query'
print("[ROUTER] Have relevant documents - generating answer")
return 'generate'
def check_answer_quality(state):
query = get_latest_user_query(state['messages'])
documents = state.get('retrieved_docs', '')
generation = state['messages'][-1].content
llm_hallucinations = llm.with_structured_output(GradeHallucinations)
response = llm_hallucinations.invoke([
SystemMessage("Grade whether the generation is grounded in the set of facts. Score 'yes' or 'no'."),
HumanMessage(f"Set of facts:\n\n{documents}\n\nLLM Generation: {generation}")
])
if response.binary_score == 'yes':
print("[ROUTER] Generation is grounded in documents")
llm_answer = llm.with_structured_output(GradeAnswer)
answer_response = llm_answer.invoke([
SystemMessage("Grade whether the answer resolves the query. Score 'yes' or 'no'."),
HumanMessage(f"User Query: {query}\n\n LLM Generation: {generation}")
])
if answer_response.binary_score == 'yes':
print('[ROUTER] generation is good. - USEFUL')
return END
else:
print("[ROUTER] Generation does not address the query - NOT USEFUL")
return "transform_query"
else:
print("[ROUTER] Generation NOT grounded in the response")
return 'generate'Building the Graph

Both gates wire into the graph: one after document grading, one after generation.
def create_self_rag():
builder = StateGraph(AgentState)
builder.add_node('retrieve', retrieve_node)
builder.add_node('grade_documents', grade_documents_node)
builder.add_node('generate', generate_node)
builder.add_node('transform_query', transform_query_node)
builder.add_edge(START, 'retrieve')
builder.add_edge('retrieve', 'grade_documents')
builder.add_edge('transform_query', 'retrieve')
builder.add_conditional_edges('grade_documents', should_generate, ['transform_query', 'generate'])
builder.add_conditional_edges('generate', check_answer_quality, ['generate', END, 'transform_query'])
return builder.compile()
agent = create_self_rag()Testing Self-RAG
A straightforward question retrieves, grades, generates, and passes both gates:
query = "What was Amazon's revenue in 2023?"
result = agent.invoke({'messages': [HumanMessage(query)]})A comparison question may rewrite the query when the first retrieval is too broad. It then regenerates until the answer is grounded and useful:
query = "Compare Apple and Amazon revenue in 2024 q1"
result = agent.invoke({'messages': [HumanMessage(query)]})
result['messages'][-1].pretty_print()Important
The double gate makes Self-RAG the strongest pattern against hallucination. An answer only reaches the user if it is both grounded in the documents and genuinely answers the question. The trade-off is more LLM calls per query.
The final lesson, Adaptive RAG, reuses these exact nodes as one of three routed paths.
What You Built
In this blog, we built a Self-RAG agent:
- Document grader: drops off-topic retrievals before generation
- Hallucination gate: checks the answer is grounded in the retrieved facts
- Usefulness gate: checks the answer actually resolves the query
- Query transformer: breaks failed queries into focused sub-queries and retries
- Two conditional gates:
should_generateandcheck_answer_qualityregenerate, rewrite, or finish
This is how Self-RAG works. It trades extra LLM calls for answers we can trust, which is the right choice when factual accuracy matters most.



